麻烦老师看一下代码
麻烦老师评论一下
还有文件备份为什么不使用shutil.copyfile()文件拷贝而是使用文件写入的方式
运行

import os
import hashlib
import shutil
import time
class FileBackup(object):
skipFile = ['']
# 忽略文件 [路径/文件名]
skipPath = []
# 忽略文件夹 [路径]
updateNum = [0, 0]
def __init__(self, src, dist):
self.src = src.strip().rstrip('/')
self.dist = dist.strip().rstrip('/')
if not os.path.isdir(self.src):
return print('> error:源文件夹不存在')
if not os.path.isdir(self.dist):
if not self.mkdir(self.dist):
return print('> 备份文件夹创建失败')
else:
print('> 备份文件夹初始化成功')
self.backup(self.src, self.dist)
print('共更新: \n\t> 文件:{}\n\t> 文件夹:{}'.format(self.updateNum[0], self.updateNum[1]))
def backup(self, src, dist):
for item in os.listdir(src):
path_src_dir = src + '/' + item
path_dist_Dir = dist + '/' + item
if os.path.isdir(path_src_dir):
# 文件夹
if path_src_dir in self.skipPath:
continue
if not os.path.isdir(path_dist_Dir):
self.mkdir(path_dist_Dir)
self.backup(path_src_dir, path_dist_Dir)
else:
# 文件
if path_src_dir in self.skipFile:
continue
# 文件对比
if os.path.isfile(path_dist_Dir):
# 文件存在
srcMd5 = self.md5_file(path_src_dir)
distMd5 = self.md5_file(path_dist_Dir)
# 文件MD5对比
if not srcMd5 == distMd5:
self.backup_file(path_src_dir, path_dist_Dir)
else:
# 拷贝
self.backup_file(path_src_dir, path_dist_Dir)
def backup_file(self, src, dist):
"""
文件拷贝
:param src: 源文件
:param dist: 备份
:return:
"""
try:
shutil.copyfile(src, dist)
print('\t拷贝成功 ' + dist)
self.updateNum[0] += 1
except:
print('\t拷贝失败 ' + dist)
def md5_file(self, path):
"""
分段计算文件MD5
:param path:
:return:
"""
m = hashlib.md5()
with open(path, 'rb') as fo:
while True:
data = fo.read(1024)
# 避免内存泄漏,分段读取
if not data:
break
m.update(data)
# 更新MD5
return m.hexdigest()
def mkdir(self, path, name=None):
"""
文件夹创建
:param path: 路径 [路径/文件夹]
:param name: 文件夹名 [None]
:return: bool
"""
if name != None:
path = path + "/" + name
path = path.strip().rstrip('/')
os.mkdir(path)
if os.path.isdir(path):
self.updateNum[1] += 1
print('> 文件夹创建成功 ' + path)
return True
else:
return False
if __name__ == '__main__':
# 目标路径
src = '/Applications/XAMPP/xamppfiles/htdocs/pro/app_manage_2/application/'
# 备份路径
dist = "/Users/apple/Desktop/back/"
FileBackup(src, dist)22
收起
正在回答
3回答

同学,你好。老师这边测试代码是无法运行的,如图:

第一句成立,则第二句永远不会成立,且每当第一句成立,第三句肯定会执行,这就导致了backup函数每循环一次就会调用一次,因此报目录结构太深的错误;
skipFile类属性里定义了,但是skipFile却没有放入数值,在没有值的情况下判断if path_src_dir in self.skipFile此句,是永远不会成立的,因此不可行。建议同学看完老师的视频根据老师的视频敲一遍代码,如果想要扩充功能,可以具体提问,会安排老师为你解答的。
祝学习愉快~
好帮手慕笑蓉
2020-04-26 11:54:38
同学,你好。是可以使用shutil.copyfile()进行文件拷贝的,但实际项目中往往需要写一些符合程序要求的拷贝方法,比如哪些文件可以拷贝,哪些不能,所以还是需要对程序的拷贝过程有一些了解。
根据同学提供的代码有以下几点需要注意:
return不要返回print()语句的数据,因为print()的没有值,只是将数据输出了,所以不要用return去返回print()数据:
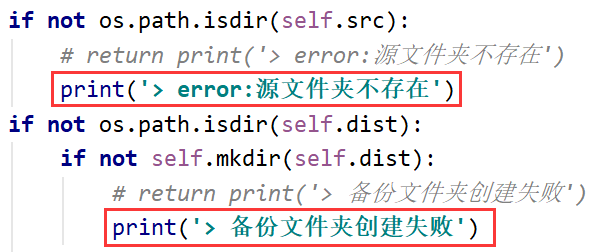
self.backup(path_src_dir, path_dist_Dir)代码反复执行,最终导致目录结构过深而报错:
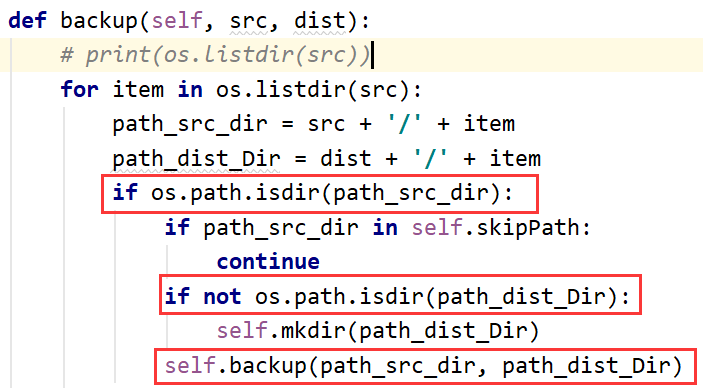
在使用self.skipFile代码时,skipFile里面还没有加入值




建议同学跟着老师的代码来,一步一步实现。
如果解决了你的疑惑,请采纳,祝学习愉快~

相似问题






登录后可查看更多问答,登录/注册
1.Python零基础入门
- 参与学习 人
- 提交作业 2727 份
- 解答问题 8160 个
想要进入Python Web、爬虫、人工智能等高薪领域,你需要掌握本阶段的Python基础知识,课程安排带你高效学习轻松入门,学完你也能听得懂Python工程师的行业梗。
了解课程











恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星