Hive shell insert 生成mapreduce 任务卡住了。时间太长了,我主动ctrl+c结束了

我的电脑性能有限,只运行了两台虚拟机。hadoop一个,flume+hive+mysql一个。flume sink hadoop操作是可以的。
hive怎么知道向bigdata01上提交任务呢?hive-env.sh 里的 HADOOP_HOME是bigdata04本地hadoop安装目录啊
我的bigdata04 也安装了 hadoop,算是个hadoop集群客户端节点吗?mapreduce任务怎么就卡住了?
正在回答

1:hive怎么知道向bigdata01上提交任务呢?hive-env.sh 里的 HADOOP_HOME是bigdata04本地hadoop安装目录啊
bigdata04中hadoop的etc/hadoop目录中的那些配置文件(最核心的是core-site.xml中的fs.defaultFs参数)和Hadoop集群中的配置文件内容是一样的,所以bigdata04知道集群的主节点是哪个节点,这样bigdata04就可以访问集群了。
2:我的bigdata04 也安装了 hadoop,算是个hadoop集群客户端节点吗?
bigdata04 节点安装了hadoop之后,需要确保hadoop目录下的etc/hadoop目录中的配置文件内容和集群中的配置文件一致,最好是把集群中的Hadoop安装包拷贝到bigdata04节点上。这样bigdata04 就是集群的客户端节点了。
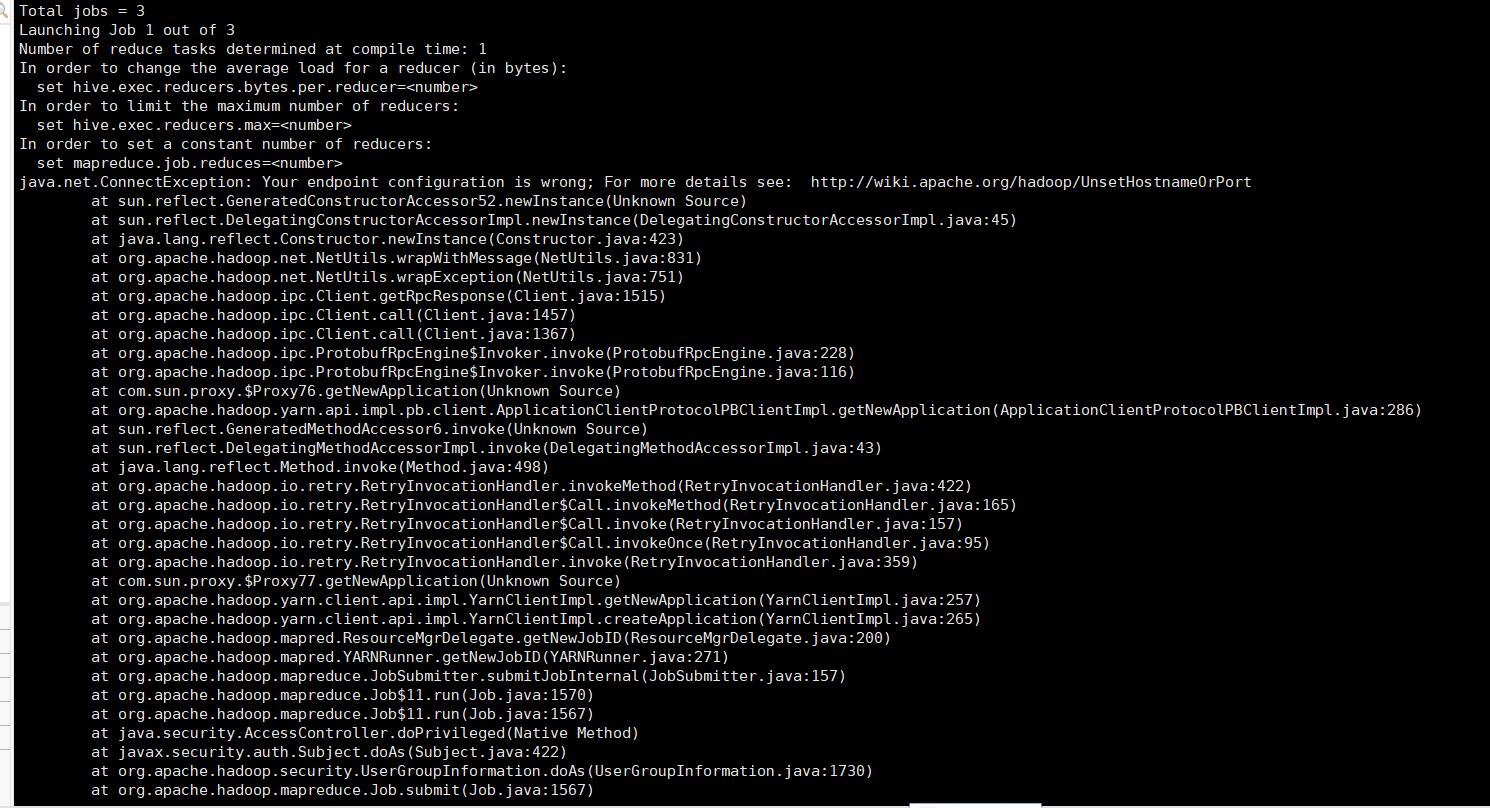
3:mapreduce任务怎么就卡住了?
mapreduce任务卡住的原因需要访问YARN的8088界面,查看一下hive提交到YARN上的这个mapreduce的日志信息,看看到底是报了什么错。
有一个比较直接的方法是这样的:在hive中执行insert之后,就一直等(有可能是由于电脑性能差导致的执行很慢)。
如果执行失败的话,控制台肯定会提示失败的,首先看一下控制台有没有抛出详细的错误信息,如果没有的话再到8088界面去查看详细的错误信息。
注意:你在hive命令行中执行ctrl+c应该是无法停止任务的,因为任务已经提交到Hadoop集群上面了,所以你还需要到YARN中确认一下上面是否有正在执行的任务,有的话使用yarn kill命令把任务杀掉即可

相似问题



登录后可查看更多问答,登录/注册










恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星