82行打印出来乱码, 要怎么解决
# coding: utf-8
import time
import requests
from lxml import etree
import pymongo
from queue import Queue
import threading
class PageThread(threading.Thread):
def __init__(self, thread_name, page_queue, detail_queue):
threading.Thread.__init__(self)
self.thread_name = thread_name
self.page_queue = page_queue
self.detail_queue = detail_queue
def run(self):
while not self.page_queue.empty():
page_url = self.page_queue.get_nowait()
page_html = get_html_by_url(page_url)
detail_html_list = page_html.xpath("//ol[@class='grid_view']/li")
for i, detail_html in enumerate(detail_html_list):
if i > 2:
break
self.detail_queue.put(detail_html)
class DetailThread(threading.Thread):
def __init__(self, thread_name, detail_queue, con, lock):
threading.Thread.__init__(self)
self.thread_name = thread_name
self.detail_queue = detail_queue
self.con = con
self.lock = lock
def run(self):
while not self.detail_queue.empty():
detail_html = self.detail_queue.get_nowait()
info_html = detail_html.xpath('//div[@class="info"]')
movie_dict = {
'movie_name': list_join(info_html.xpath("./div[@class='hd']/a/span/text()")),
'actors_information': list_join(info_html.xpath("./div[@class='bd']/p[1]/text()")),
'score': list_join(info_html.xpath("./div[@class='bd']/div/span[@class='rating_num']/text()")),
'evaluate': list_join(info_html.xpath("./div[@class='bd']/div/span[last()]/text()")),
'describe': list_join(info_html.xpath("./div[@class='bd']//span[@class='inq']"))
}
print(movie_dict)
# with self.lock:
# self.con.insert_one(movie_dict)
def list_join(l):
return ''.join(l)
def get_html_by_url(url):
print(url)
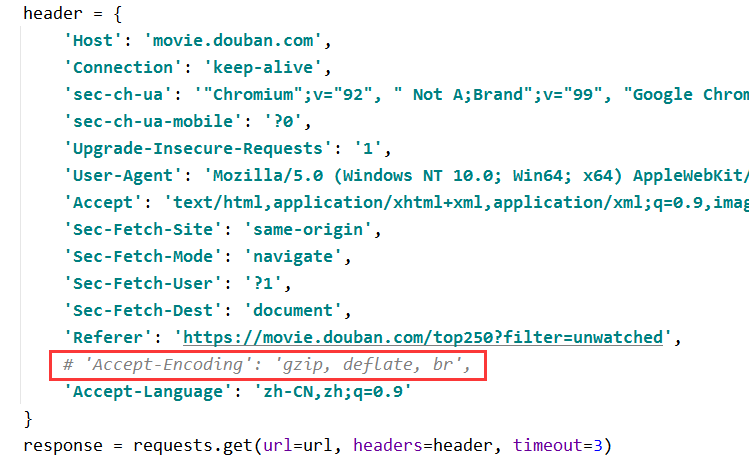
header = {
'Host': 'movie.douban.com',
'Connection': 'keep-alive',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Referer': 'https://movie.douban.com/top250?filter=unwatched',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
response = requests.get(url=url, headers=header, timeout=3)
with open('douban.html', 'wb') as f:
t = response.content
f.write(t)
text = response.text
print(text)
html = etree.HTML(response.text)
html_str = etree.tostring(html).decode()
return html
def main():
page_queue = Queue()
detail_queue = Queue()
con = pymongo.MongoClient(host='127.0.0.1', port=1112)['douban']['movie250']
lock = threading.Lock()
# for i in range(0, 100, 25):
# for i in range(0, 50, 25):
# url = f'https://movie.douban.com/top250?start={i}'
# page_queue.put(url)
url = f'https://movie.douban.com/top250?start=0'
page_queue.put(url)
page_thread_names = ['页面线程1', '页面线程2', '页面线程3']
page_thread_list = []
for page_thread_name in page_thread_names:
page_thread = PageThread(page_thread_name, page_queue, detail_queue)
page_thread.start()
page_thread_list.append(page_thread)
while not page_queue.empty():
pass
for page_thread in page_thread_list:
if page_thread.is_alive():
page_thread.join()
detail_thread_names = ['详情线程1', '详情线程2', '详情线程3', '详情线程4', '详情线程5']
detail_thread_list = []
for detail_thread_name in detail_thread_names:
detail_thread = DetailThread(detail_thread_name, detail_queue, con, lock)
detail_thread.start()
detail_thread_list.append(detail_thread)
while not detail_queue.empty():
pass
for detail_thread in detail_thread_list:
if detail_thread.is_alive():
detail_thread.join()
if __name__ == '__main__':
start_time = time.time()
main()
end_time = time.time()
print('耗时{}秒'.format(end_time - start_time))
29
收起
正在回答 回答被采纳积分+1
1回答



相似问题









登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星