老师我这图片下载不了
pipelines.py
# Define your item pipelines here
#
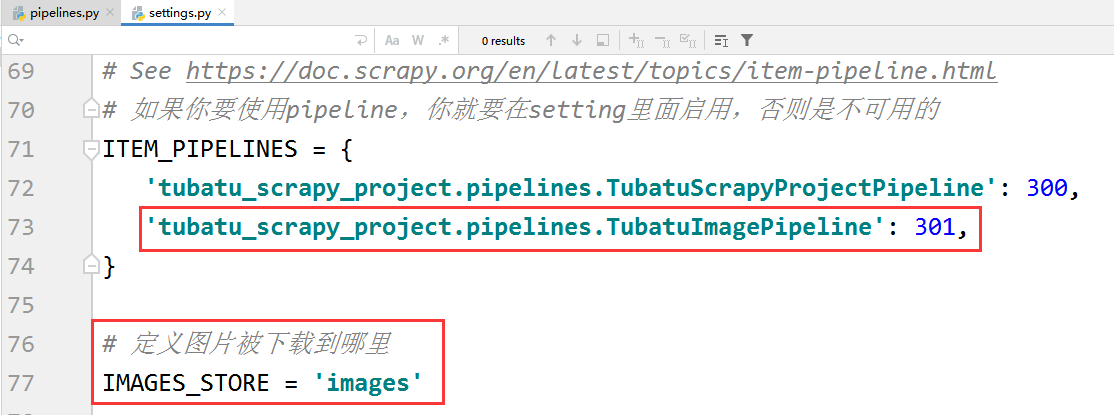
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymongo
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class TubatuScrapyProjectPipeline:
def __init__(self):
myclient = pymongo.MongoClient("mongodb://106.12.9.193:27017", username="admin", password="123456")
mydb = myclient['db_tubatu']
self.mycollection = mydb['collection_tubatu']
def process_item(self, item, spider):
data = dict(item)
self.mycollection.insert_one(data)
return item
# 自定义的图片下载类需要继承于ImagesPipeline
class TubatuImagePipeline(ImagesPipeline):
# def get_media_requests(self, item, info):
# # 根据image_urls中指定URL爬取
# pass
def item_completed(self, results, item, info):
# 图片下载完毕之后,处理结果的,返回是一个二元组
# (success, image_info_or_failure)
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Item contains no images')
return item
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
这是我pipelines文件的代码,运行以后存储到了数据库但是没有解析图片下载,也没有帮错
31
收起
正在回答 回答被采纳积分+1








Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星