正在回答 回答被采纳积分+1
1回答

时间,
2021-09-05 18:31:50
同学,你好!
爬虫中间件Spider Middleware:主要功能是在爬虫运行过程中进行一些处理。主要用于处理Spider的Responses和Requests
下载器中间件Downloader Middleware:主要功能在请求到网页后,页面被下载时进行一些处理。主要用于处理Scrapy引擎与下载器之间的请求及响应。
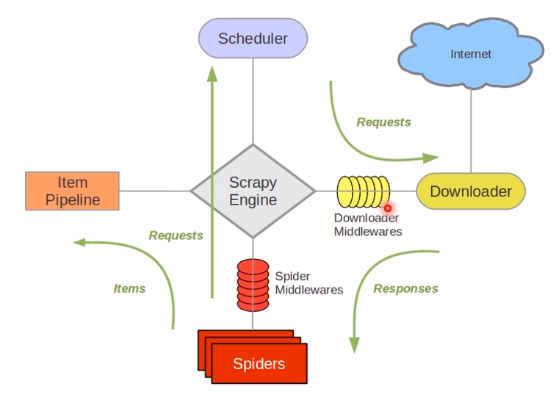
Scrapy Engine(引擎):用来处理整个系统的数据传递,是整个系统的核心部分。
Scheduler(调度器):用来接受引擎发过来的Request请求, 压入队列中, 并在引擎再次请求的时候返回。
Downloader(下载器):用于引擎发过来的Request请求对应的网页内容, 并将获取到的Responses返回给Spider。
Item Pipeline(管道):负责处理Spider中获取的实体,对数据进行清洗,保存所需的数据。 Downloader
Middlewares(下载器中间件):主要用于处理Scrapy引擎与下载器之间的请求及响应。
SpiderMiddlewares(爬虫中间件):主要用于处理Spider的Responses和Requests
祝学习愉快!
相似问题







登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星