正在回答 回答被采纳积分+1
2回答



相似问题
请问能解释一个网址和url的区别吗?
12
0
3


慕旅游网址
16
0
3


怎么区分IP地址的网络部分?
22
0
3


phpstudy用ip地址登录网站
13
0
3


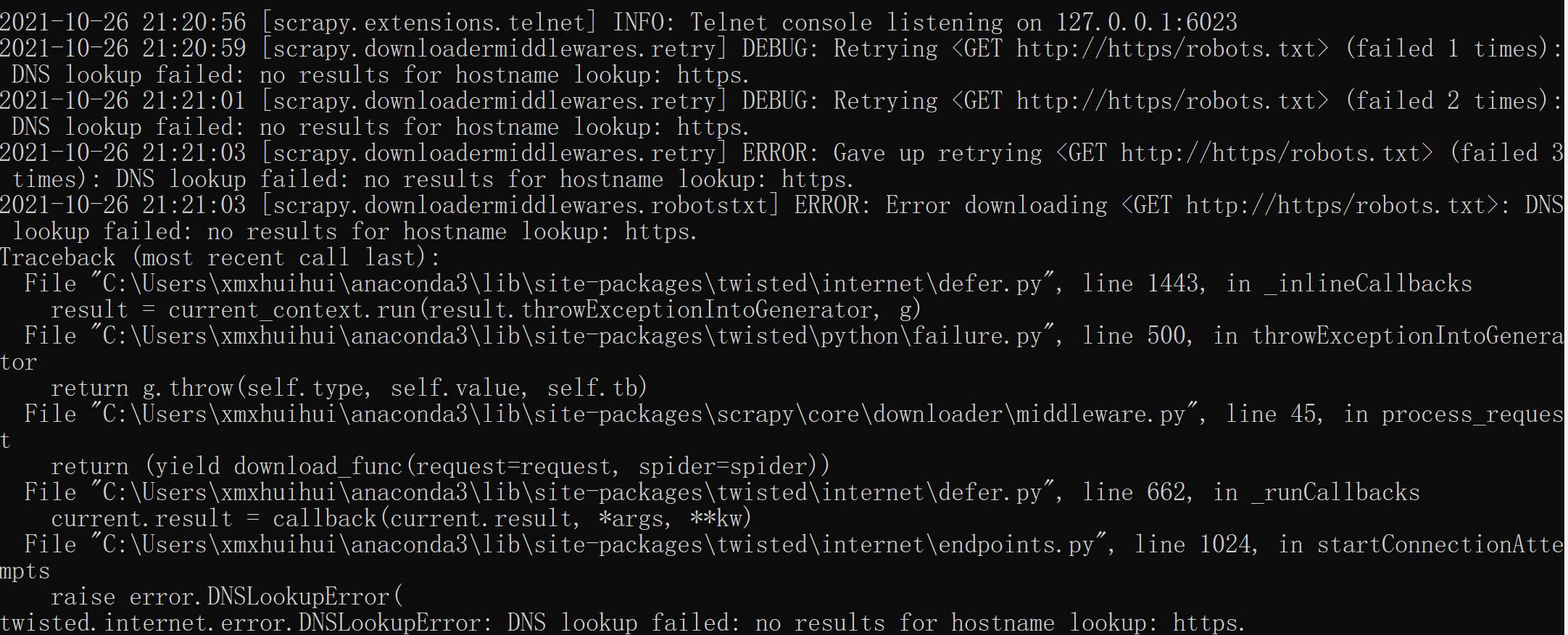
关于局部httpps安全问题
22
0
8
登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星