正在回答 回答被采纳积分+1
1回答

时间,
2021-10-26 10:15:38
同学,你好!
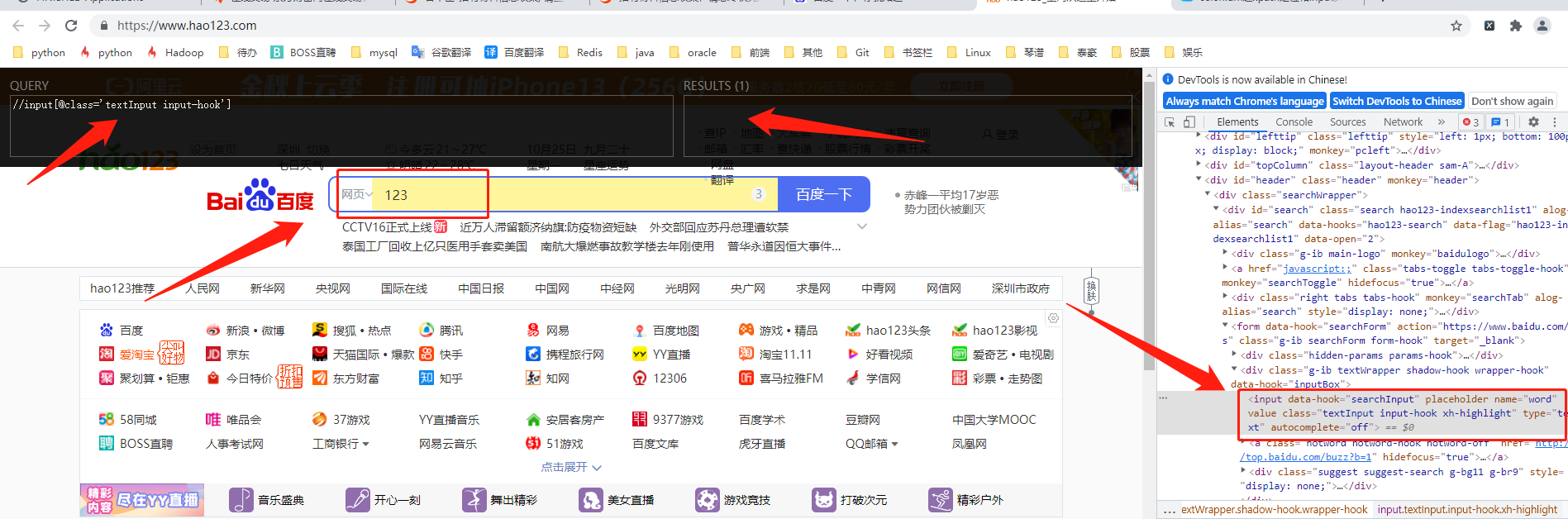
1、只是在input标签中输入内容是获取不到内容的,需要点击"百度一下"之后跳转到新的页面,访问该页面才可以获取到
例:
import requests
from lxml import etree
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36"
}
url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=1258&fen%27%20\%20%27lei=256&rsv_pq=fbadbbb1000e56de&rsv_t=20daYbdZrZl5XR9Cuw1%2FwojIiJf0i463f42bshs%27%20\%20%27HbfifbU77d4Z2i0Xj3PQ&rqlang=cn&rsv_enter=0&rsv_dl=tb&rsv_btype=i&inputT=1833&rsv_su%27%20\%20%27g4=2321'
response = requests.get(url=url, headers=header)
html = etree.HTML(response.text)
items = html.xpath("//input[@id='kw']/@value")
print(items) # ['1258']祝学习愉快!






Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星