代码有什么问题
import requests
import pymongo
from queue import Queue
from lxml import etree
import threading
def handle_request(url):
"""
处理request函数
:param url:
:return:
"""
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
response = requests.get(url=url, headers=headers, timeout=(5, 5), proxies=None)
if response.status_code == 200 and response:
return response.text
class PageSpider(threading.Thread):
#页码URL请求多线程爬虫
def __init__(self,thread_name, page_queue, detail_queue):
super(PageSpider, self).__init__()
self.thread_name= thread_name
self.detail_queue = detail_queue
self.page_queue = page_queue
def parse_detail_url(self,content):
"""
处理page_url页面返回的数据,解析详情页的URL
:param content:page_response.text
:return:detail_url, 放入self.detail_queue
"""
#页码数据实例化
item_html = etree.HTML(content)
#解析所有详情页URL
detail_urls= item_html.xpath("//a[@class='thumbnail']/@href")
for detail_url in detail_urls:
#将详情页放入队列中
self.detail_queue.put(detail_url)
def run(self):
#实际发送请求,请求页码URL
print('{}启动'.format(self.thread_name))
#需要不断从页码QUEUE里面获取URL, 并且发送请求,要看self.page_queue是否为空
try:
while not self.page_queue.empty():
page_url = self.page_queue.get(block=False)
page_response = handle_request(url=page_url)
if page_response:
#解析30条详情页的URL
self.parse_detail_url(content=page_response)
except Exception as e:
print('{} run error:{}'.format(self.thread_name, e))
print("{}结束".format(self.thread_name))
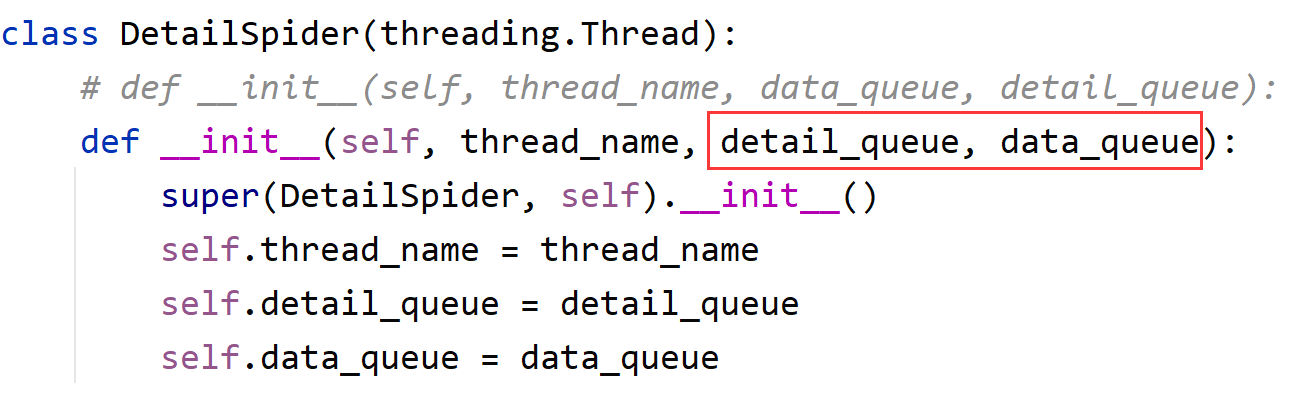
class DetailSpider(threading.Thread):
def __init__(self,thread_name, data_queue, detail_queue):
super(DetailSpider, self).__init__()
self.thread_name= thread_name
self.detail_queue = detail_queue
self.data_queue = data_queue
def run(self):
#实际发送请求,请求页码URL
print('{}启动'.format(self.thread_name))
#需要不断从页码QUEUE里面获取URL, 并且发送请求,要看self.page_queue是否为空
try:
#从detail_queue获取90个详情页的URL
while not self.detail_queue.empty():
detail_url = self.detail_queue.get(block=False)
detail_response = handle_request(url=detail_url)
if detail_response:
#解析30条详情页的URL
self.data_queue.put(detail_response)
except Exception as e:
print('{} run error:{}'.format(self.thread_name, e))
print("{}结束".format(self.thread_name))
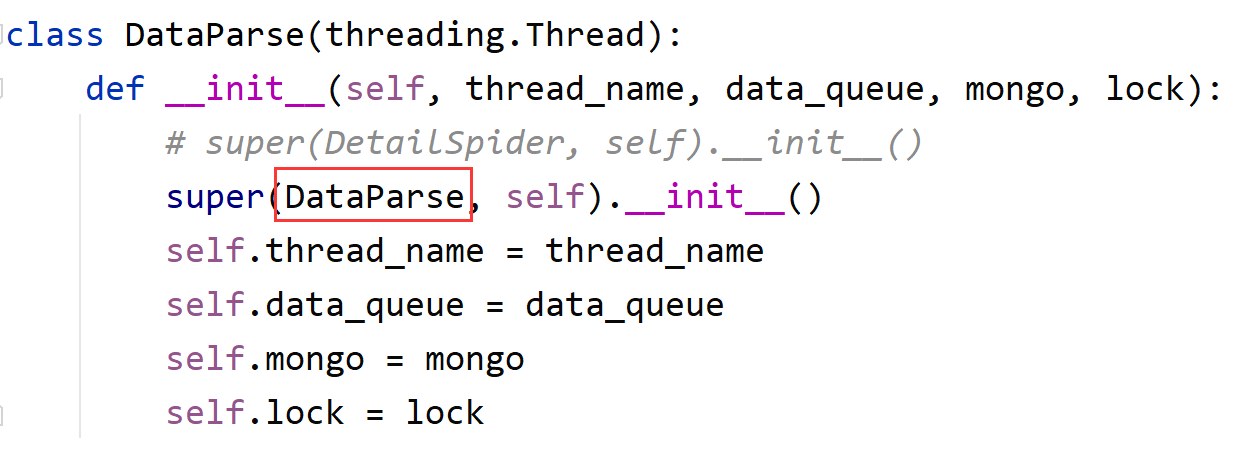
class DataParse(threading.Thread):
def __init__(self,thread_name, data_queue, mongo, lock):
super(DetailSpider, self).__init__()
self.thread_name= thread_name
self.data_queue = data_queue
self.mongo = mongo
self.lock = lock
def _join_list(self,item):
return ''.join(item)
def parse(self, data):
"""
解析data_queue数据
:param data:data_queue.get()
:return:pymongo
"""
#实例化HTML数据
html = etree.HTML(data)
info = {
'title':self._join_list(html.xpath('//div[@class="page-header"]/h1/text()')),
"update_time": self._join_list(html.xpath("//div[@class='panel-body']/p[1]/text()")),
"type": self._join_list(html.xpath("//div[@class='panel-body']/p[2]/text()")),
"starring": self._join_list(html.xpath("//div[@class='panel-body']/p[3]/text()")),
"desc": self._join_list(html.xpath("//div[@class='panel-body']/p[4]/text()")),
"download_url": self._join_list(html.xpath("//div[@class='panel-body']/p[5]/text()")),
"source_url": self._join_list(html.xpath("//div[@class='panel-body']/p[6]/a/text()"))
}
# 由于是多线程并发插入数据,因此使用lock来进行控制
with self.lock:
self.mongo.insert_one(info)
def run(self):
#实际发送请求,请求页码URL
print('{}启动'.format(self.thread_name))
#需要不断从页码QUEUE里面获取URL, 并且发送请求,要看self.page_queue是否为空
try:
#从data_queue获取90个详情页的URL
while not self.data_queue.empty():
detail_info = self.data_queue.get(block=False)
#xpath解析网页数据
self.parse(detail_info)
except Exception as e:
print('{} run error:{}'.format(self.thread_name, e))
print("{}结束".format(self.thread_name))
def main():
#页码队列
page_queue= Queue()
for i in range(1, 4):
page_url= 'http://movie.54php.cn/movie/?&p={}'.format(i)
page_queue.put(page_url)
# 电影详情页URL队列
detail_queue = Queue()
# 详情页数据对列
data_queue = Queue()
#第一个爬虫
page_spider_threadname_list = ['列表线程1号','列表线程2号', '列表线程3号']
page_spider_list = []
for thread_name in page_spider_threadname_list:
thread = PageSpider(thread_name, page_queue, detail_queue)
thread.start()
page_spider_list.append(thread)
#查看当前page_queue里面数据状态
while not page_queue.empty():
pass
#释放资源
for thread in page_spider_list:
if thread.is_alive():
thread.join()
#第二个爬虫
detail_spider_threadname_list = ['详情线程1号', '详情线程2号', '详情线程3号', '详情线程4号', '详情线程5号']
detail_spider_list = []
for thread_name in detail_spider_threadname_list:
thread = DetailSpider(thread_name, detail_queue, data_queue)
thread.start()
detail_spider_list.append(thread)
# 查看当前detail_queue里面数据状态
while not detail_queue.empty():
pass
for thread in detail_spider_list:
if thread.is_alive():
thread.join()
# print(data_queue.qsize())
#第三个爬虫
#使用lock,向mongo插入数据
lock = threading.Lock()
client= pymongo.MongoClient(host='127.0.0.1',port=1112)
mydb = client['db_movie']
mycollection = mydb['movie_info']
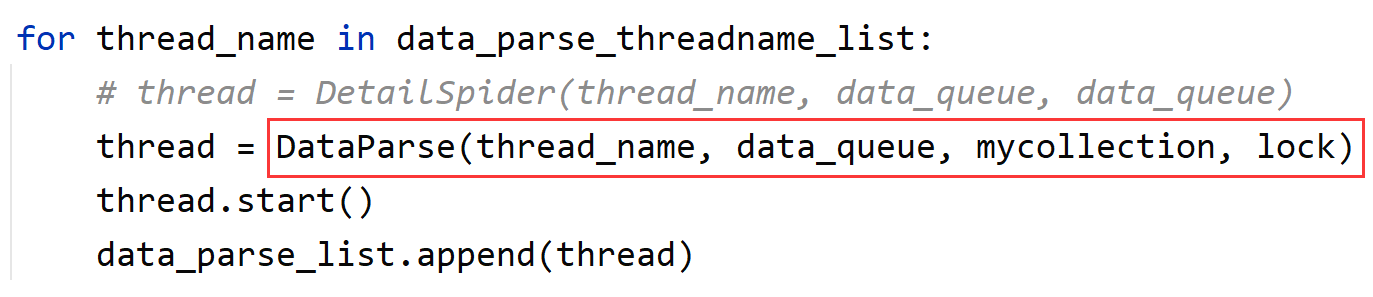
data_parse_threadname_list = ['数据线程1号', '数据线程2号', '数据线程3号', '数据线程4号', '数据线程5号']
data_parse_list = []
for thread_name in data_parse_threadname_list:
thread = DetailSpider(thread_name, data_queue, data_queue)
thread.start()
data_parse_list.append(thread)
# 查看当前detail_queue里面数据状态
while not data_queue.empty():
pass
for thread in data_parse_list:
if thread.is_alive():
thread.join()
if __name__=='__main__':
main()列表线程1号启动
列表线程2号启动
列表线程3号启动
列表线程3号结束
列表线程1号结束
列表线程2号结束
详情线程1号启动
详情线程1号结束
详情线程2号启动
详情线程2号结束
详情线程3号启动
详情线程3号结束
详情线程4号启动
详情线程4号结束
详情线程5号启动
详情线程5号结束
循环到这之后没有了,一直循环什么问题
9
收起
正在回答 回答被采纳积分+1
1回答


相似问题








登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程













恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星