桶表作用
桶表作用:
一、数据抽样疑问:
测试语句:
select * from bucket_tb tablesample(bucket 1 out of 4 on id); ---桶表
select * from b_source tablesample(bucket 1 out of 4 on id); ---普通表
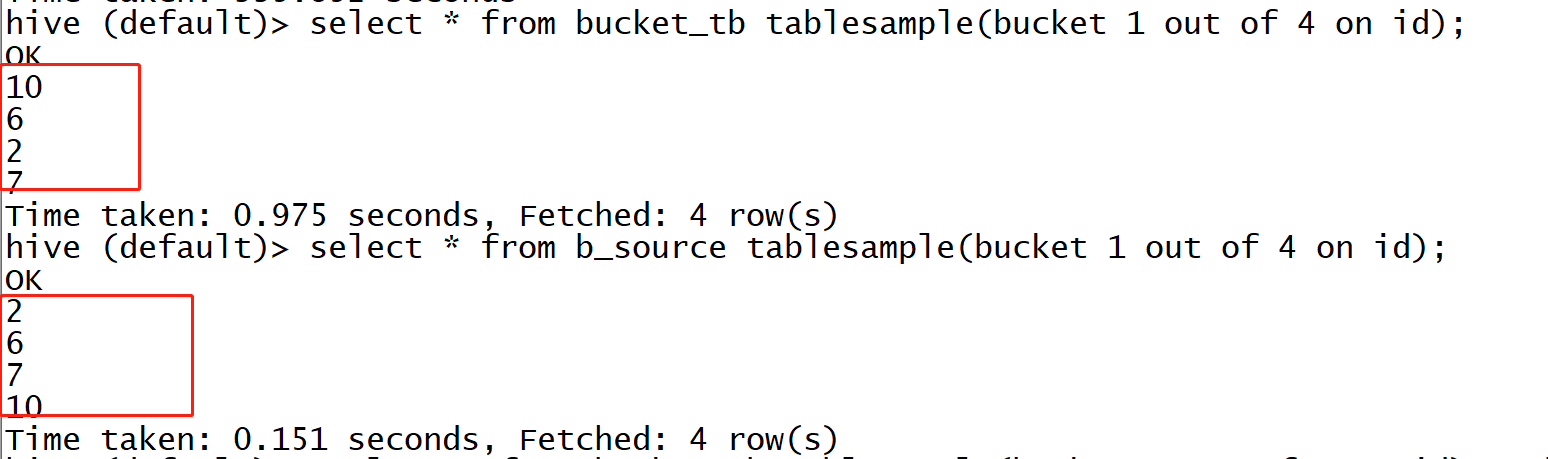
经过测试,select * from 表 tablesample(bucket 1 out of 4 on id);语句中“表”并非只是针对桶表,普通表也可以进行此抽样 且 tablesample(bucket 1 out of 4 on id)会重新针对id进行分桶。所以,没有太明白此处桶表在数据抽样中作用体现在哪?且如果分桶因子不一致,那之前分桶其实会带来额外开销。
二、提升join效率疑问:
在使用a.id=b.id join时,此时应该不是笛卡儿积,应该是先匹配id是否相等,此时无论是否桶表都需要先拿出id匹配,而桶表分为几个文件存储感觉会更影响效率。【笛卡儿积应该是没有任何条件两表关联才会出现,若有条件不会出现笛卡儿积】;
正在回答

1:tablesample抽样可以针对所有表,但是针对桶表抽样效率会更高。
针对这两个SQL,通过查询查询计划,可以看到如下效果:
select * from bucket_tb tablesample(bucket 1 out of 4 on id);的查询计划如下:
hive> explain select * from bucket_tb tablesample(bucket 1 out of 4 on id); OK STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: TableScan alias: bucket_tb Statistics: Num rows: 12 Data size: 15 Basic stats: COMPLETE Column stats: NONE Filter Operator predicate: (((hash(id) & 2147483647) % 4) = 0) (type: boolean) Statistics: Num rows: 6 Data size: 7 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: id (type: int) outputColumnNames: _col0 Statistics: Num rows: 6 Data size: 7 Basic stats: COMPLETE Column stats: NONE ListSink Time taken: 0.196 seconds, Fetched: 20 row(s)
这里面处理的数据量在15字节。Statistics: Num rows: 12 Data size: 15 Basic stats: COMPLETE Column stats: NONE
select * from b_source tablesample(bucket 1 out of 4 on id);的查询计划如下:
hive> explain select * from b_source tablesample(bucket 1 out of 4 on id); OK STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: TableScan alias: b_source Statistics: Num rows: 1 Data size: 270 Basic stats: COMPLETE Column stats: NONE Filter Operator predicate: (((hash(id) & 2147483647) % 4) = 0) (type: boolean) Statistics: Num rows: 1 Data size: 270 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: id (type: int) outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 270 Basic stats: COMPLETE Column stats: NONE ListSink Time taken: 0.149 seconds, Fetched: 20 row(s)
这里面处理的数据量在270字节:Statistics: Num rows: 1 Data size: 270 Basic stats: COMPLETE Column stats: NONE。
2:
在使用a.id=b.id join时,不会产生笛卡儿积。
桶表在使用分桶字段在join的时候,可以进一步提升效率,这个也可以通过explain看出来。
桶表join时计算的数据量比普通表小。
根据b_source表再创建一个b_source_2表。
根据bucket_tb表再创建一个bucket_tb_2表。
分别对这些表进行join,分析explain执行计划,可以看出来桶表在join时需要计算的数据量比普通表小,所以桶表在计算时性能会更高。
explain select a.id from bucket_tb as a join bucket_tb_2 b on a.id = b.id explain select a.id from b_source as a join b_source_2 b on a.id = b.id












恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星