跪求大神指点
课外提问,求大神指点
题目:利用Feapder框架,爬取http://www.cae.cn/cae/html/main/col48/column_48_1.html
工程院院士的信息
代码:
# -*- coding: utf-8 -*-
"""
Created on 2021-12-03 20:30:27
---------
@summary:
---------
@author: DELL
"""
import feapder
import time
Name = []
list_all = [] # 创建空列表,用于下面存储数据
urls = []
target2 = 'https://www.cae.cn'
def write(name, text):
text_name = '文本1.txt'
with open (text_name, 'a+', encoding='utf-8') as m:
m.write(name +'\n')
m.writelines(text.replace('&ensp', ' ').replace(';','').lstrip())
m.write('\n\n')
class TargetSpider(feapder.AirSpider):
def start_requests(self): # 生产任务
url = 'http://www.cae.cn/cae/html/main/col48/column_48_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
yield feapder.Request(url, headers=headers, render = True)
def parse(self, request, response): # 解释
card_elements = response.xpath('li',class_ = 'name_list')
for i in card_elements:
Continue_card = i.xpath('a')
global Name
Name.append(Continue_card[0].string) # 获取每个链接的名字
global list_all
for j in Continue_card:
temp1 = j.xpath('href').extract_first()
list_all.append(temp1)
for k in list_all:
temp2 = k.xpath('div', class_ = 'intro')
temp3 = temp2.xpath('p')
write(Name[k],temp3)
if __name__ == "__main__":
TargetSpider().start()
下面是HTML的格式:
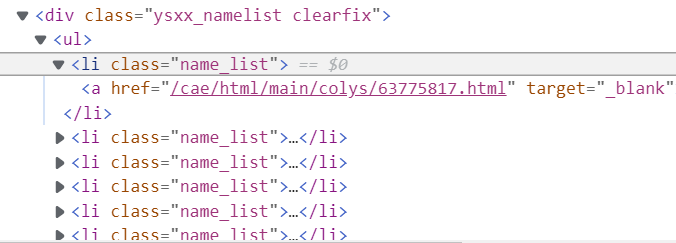
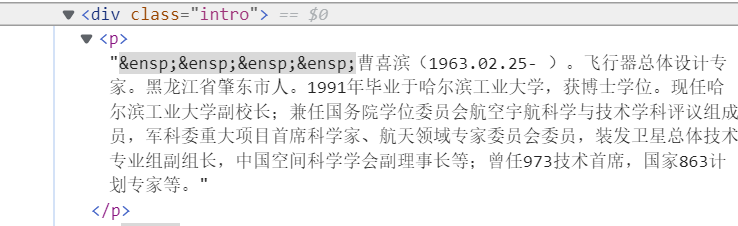
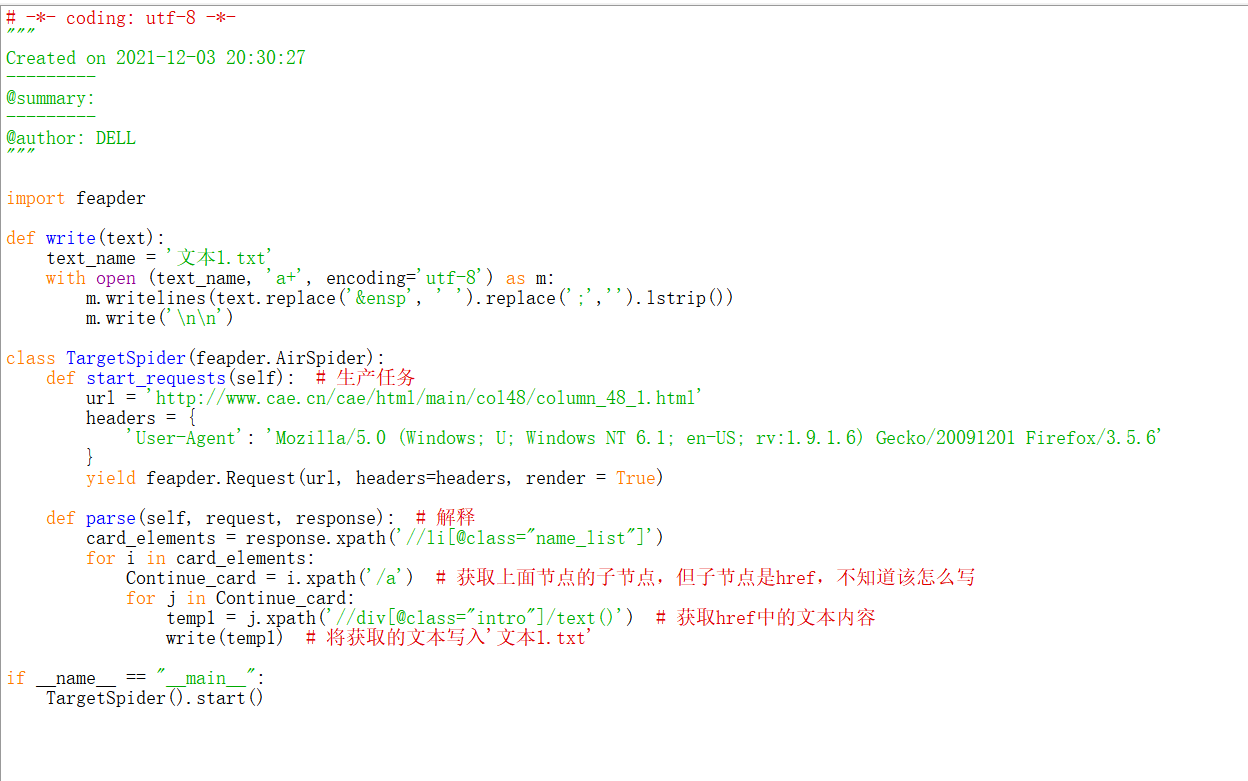
代码图片:


问题:编写的代码爬取的时候一直报错
求大神指点
正在回答 回答被采纳积分+1







- 参与学习 人
- 提交作业 16425 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程












恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星