from scrapy_redis.spiders import RedisSpider报错
#get_moive.py
import scrapy
from imooc_movie.items import ImoocMovieItem
from scrapy_redis.spiders import RedisSpider
class GetMoiveSpider(RedisSpider):
name = 'get_movie'
# allowed_domains = ['54php.cn']
# start_urls = ['http://movie.54php.cn/movie/?&p=1']
redis_key = "get_movie:start_urls"
def parse(self, response):
#获取每一页电影的items
movies_items=response.xpath("//div[@class='col-xs-12 col-sm-6 col-md-4 col-lg-2']")
for item in movies_items:
#获取详情页的URL
detail_url=item.xpath(".//a[@class='thumbnail']/@href").extract_first()
yield scrapy.Request(url=detail_url,callback=self.parse_detail)
next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first()
if next_page:
next_page_url="http://movie.54php.cn"+next_page
yield scrapy.Request(url=next_page_url,callback=self.parse)
def parse_detail(self,response):
'''
解析详情页
:param response:
:return:
'''
moive_info=ImoocMovieItem()
moive_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first()
moive_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first()
moive_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first()
print(moive_info)
yield moive_info#报错信息
C:\python3\python.exe C:\Users\Zhuang\Desktop\imooc\Scrapy_redis分布式爬虫\imooc_movie\main.py
Traceback (most recent call last):
File "C:\Users\Zhuang\Desktop\imooc\Scrapy_redis分布式爬虫\imooc_movie\main.py", line 2, in <module>
cmdline.execute("scrapy crawl get_movie".split())
File "C:\python3\lib\site-packages\scrapy\cmdline.py", line 144, in execute
cmd.crawler_process = CrawlerProcess(settings)
File "C:\python3\lib\site-packages\scrapy\crawler.py", line 280, in __init__
super().__init__(settings)
File "C:\python3\lib\site-packages\scrapy\crawler.py", line 152, in __init__
self.spider_loader = self._get_spider_loader(settings)
File "C:\python3\lib\site-packages\scrapy\crawler.py", line 146, in _get_spider_loader
return loader_cls.from_settings(settings.frozencopy())
File "C:\python3\lib\site-packages\scrapy\spiderloader.py", line 67, in from_settings
return cls(settings)
File "C:\python3\lib\site-packages\scrapy\spiderloader.py", line 24, in __init__
self._load_all_spiders()
File "C:\python3\lib\site-packages\scrapy\spiderloader.py", line 51, in _load_all_spiders
for module in walk_modules(name):
File "C:\python3\lib\site-packages\scrapy\utils\misc.py", line 88, in walk_modules
submod = import_module(fullpath)
File "C:\python3\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1050, in _gcd_import
File "<frozen importlib._bootstrap>", line 1027, in _find_and_load
File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 688, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "C:\Users\Zhuang\Desktop\imooc\Scrapy_redis分布式爬虫\imooc_movie\imooc_movie\spiders\get_movie.py", line 4, in <module>
from scrapy_redis.spiders import RedisSpider
File "C:\python3\lib\site-packages\scrapy_redis\spiders.py", line 4, in <module>
from collections import Iterable
ImportError: cannot import name 'Iterable' from 'collections' (C:\python3\lib\collections\__init__.py)
Process finished with exit code 125
收起
正在回答 回答被采纳积分+1
1回答

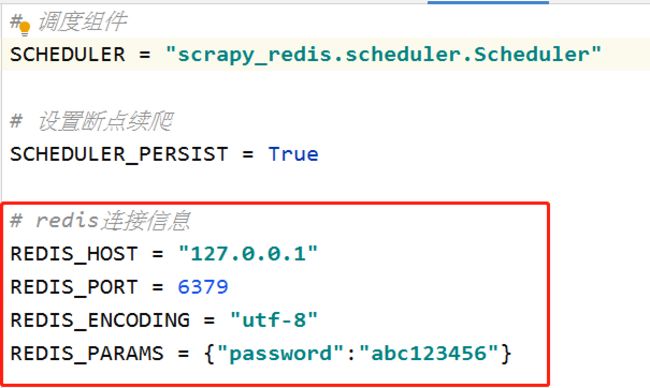
 pycharm一直提示info 0page,老师我把整个程序打包发到
pycharm一直提示info 0page,老师我把整个程序打包发到相似问题





登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星