scrapy只能获取最后一张图片
import scrapy
import re
from venv.moc.parsetest.scrapy001.scrapy_project.tubatu.items import TubatuItem
class TuvatuSpider(scrapy.Spider):
name = 'tubatu'
allowed_domains = ['to8to.com']
start_urls = ['https://xiaoguotu.to8to.com/case/type3/p1.html']
def parse(self, response):
print(response.request.headers)
pic_item_list = response.xpath('//div[@class = "item"]')
for item in pic_item_list:
info ={}
info["content_name"] = item.xpath('.//div//a[@class="title"]/text()').extract_first().replace('\n','')
info["content_url"] = item.xpath('.//div//a[@class="title"]/@href').extract_first()
yield scrapy.Request(info["content_url"],callback=self.hanle_pic_parse,meta=info)
break
# if response.xpath("//a[@id='nextpageid']"):
# now_page = int(response.xpath("//div[@class='pages']/strong/text()").extract_first())
# next_page_url = 'https://xiaoguotu.to8to.com/case/type3/p%d.html' % (now_page + 1)
# # print(now_page)
# yield scrapy.Request(url=next_page_url, callback=self.parse)
# for i in range(2,3):
# next_url = 'https://xiaoguotu.to8to.com/case/type3/p%d.html' % (i)
# print("当前爬取第{}页".format(i))
# yield scrapy.Request(url=next_url, callback=self.parse)
def hanle_pic_parse(self,response):
tubatu_info = TubatuItem()
tubatu_info["content_name"] = response.request.meta["content_name"]
tubatu_info["content_url"] = response.request.meta["content_url"]
# tubatu_info['case_designer'] = response.xpath('//div[@class="small-avatar"]//div/img/@alt').extract_first()
tubatu_info['house_type'] = response.xpath('//div[@class="info-wrapper"]//span[1]/a/text()').extract_first()
tubatu_info['house_style'] = response.xpath('//div[@class="info-wrapper"]//span[2]/a/text()').extract_first()
tubatu_info['area'] = response.xpath('//div[@class="info-wrapper"]//span[3]/a/text()').extract_first()
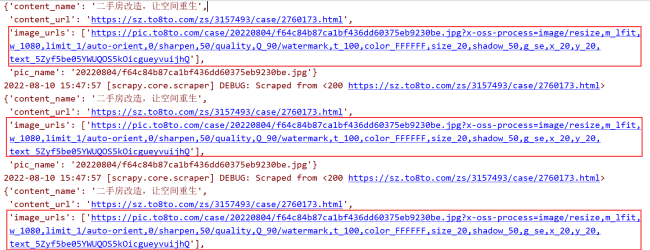
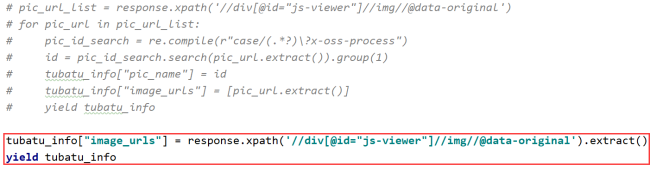
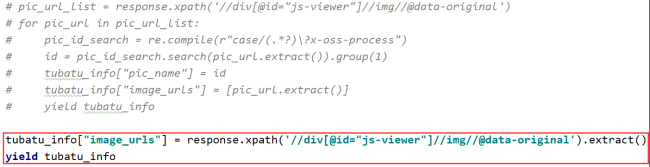
pic_url_list = response.xpath('//div[@id="js-viewer"]//img//@data-original')
for pic_url in pic_url_list:
pic_id_search = re.compile(r"case/(.*?)\?x-oss-process")
id = pic_id_search.search(pic_url.extract()).group(1)
tubatu_info["pic_name"] = id
tubatu_info["image_urls"] = [pic_url.extract()]
yield tubatu_info相关代码:
import pymongo
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
class TubatuPipeline(object):
def __init__(self):
myclient = pymongo.MongoClient(host='linzpao.zjjy.vip',port=27017,username='linzpao-admin', password='linzpao123')
mydb = myclient['linzpao']
self.mycollection =mydb['tubutu']
def process_item(self, item, spider):
# self.mycollection.delete_many({})
data = dict(item)
self.mycollection.insert_one(data)
return item
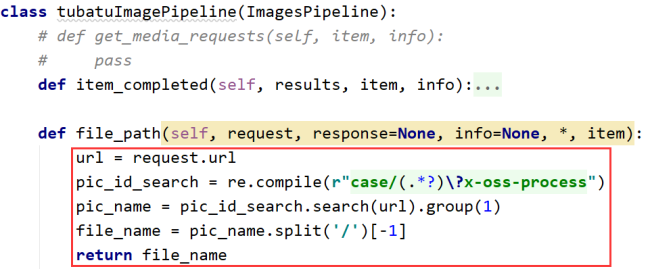
class tubatuImagePipeline(ImagesPipeline):
# def get_media_requests(self, item, info):
# pass
def item_completed(self, results, item, info):
image_paths = [x ['path']for ok,x in results if ok]
if not image_paths:
raise DropItem('item contains no images')
return item
def file_path(self, request, response=None, info=None, *, item):
print(item['pic_name'])
file_name= item['pic_name'].split('/')[-1]
return file_name问题描述:
请老师帮我看看,为什么每个主题只能获取一张图片
13
收起
正在回答 回答被采纳积分+1
1回答








Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星