请问Selenium能采用多线程吗?
问题描述:
请老师帮我看看怎么回事?代码中采用几个进程,爬取的数据就重复几次,且重复数据均是第一页~~
相关代码:
import time
import threading
import queue
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymongo
# 设置浏览器参数
chrome_options = Options()
# 设置浏览器的无头浏览器,无界面,浏览器将不提供界面,linux操作系统无界面情况下就可以运行了
chrome_options.add_argument("--headless")
# 结果devtoolsactiveport文件不存在的报错
chrome_options.add_argument("--no-sandbox")
# 官方推荐的关闭选项,规避一些BUG
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_argument('User-Agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"')
chrome_options.add_argument(r"user-data-dir=C:\Users\Administrator\AppData\Local\Google\Chrome\User Data")
# 链接数据库
client = pymongo.MongoClient(host='linzpao.zjjy.vip',port=27017,username='linzpao-admin', password='linzpao123')
mydb = client["linzpao"]
mycollection = mydb['fy']
mycollection.delete_many({})
q_url = queue.Queue()
q_parse_student = queue.Queue()
def parse_student(name):
while True:
if q_parse_student.empty():
break
# print(name + "开始")
content = q_parse_student.get(block=False)
student_web = webdriver.Chrome(options=chrome_options)
student_web.maximize_window()
student_web.get(content)
student_id = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[2]/td[2]').text
student_name = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[3]/td[2]').text
student_sex = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[4]/td[2]').text
student_college = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[5]/td[2]').text
student_class = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[6]/td[2]').text
student_phone = student_web.find_element_by_xpath('//div[3]/div/div[2]/div/table/tbody/tr[7]/td[2]').text
student_info ={
'student_id':student_id,'student_name':student_name,'student_sex':student_sex,
'student_class':student_class,'student_phone':student_phone,'student_college':student_college
}
print(student_info)
mycollection.insert_one(student_info)
# print(name + "结束")
student_web.quit()
def main(name):
while True:
if q_url.empty():
break
print(name+"开始")
page = q_url.get(block=False)
web = webdriver.Chrome(options=chrome_options)
web.maximize_window()
web.get(page)
students_id = web.find_elements_by_xpath('//tr[position()>1]//td[2]/a')
for url in students_id:
student_url =url.get_attribute('href')
print(student_url)
q_parse_student.put(student_url)
print(name+"结束")
web.quit()
# parse_student(student_url)
if __name__ == '__main__':
for i in range(1,3):
url = 'https://fyjy.eduw.cn/sysadmins/stu/stu_list.aspx?fst=186&snd=338&thd=&order=&s=0&pagecount=&xh=&xm=&yx=&bj=&sf=&cs=&sslh=&ssch=&page={}'.format(i)
print(url)
q_url.put(url)
time.sleep(2)
page_spider_threadname_list = ["列表页采集线程1号","列表页采集线程2号"]
page_spider_list = []
for thread_name in page_spider_threadname_list:
thread= threading.Thread(target=main,args=(thread_name,))
thread.start()
page_spider_list.append(thread)
for thread in page_spider_list:
if thread.is_alive():
thread.join()
detail_spider_threadname_list = ["详情页采集线程1号","详情页采集线程2号"]
detail_spider_list = []
for thread_name in detail_spider_threadname_list:
thread = threading.Thread(target=parse_student, args=(thread_name,))
thread.start()
detail_spider_list.append(thread)
for thread in detail_spider_list:
if thread.is_alive():
thread.join()相关截图:
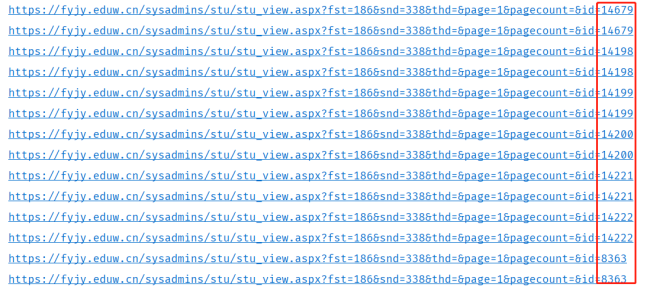

11
收起
正在回答 回答被采纳积分+1
1回答

相似问题
能不能讲一下多进程/多线程是个啥?
6
0
3


多线程如何具体应用到spring cloud 项目中?
111
0
17




多线程等于多个请求?
29
1
3
线程池数量
19
0
4




线程的问题
23
1
7


登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星