無法將圖片加載到資料夾
scrapy
re
TubatuSpider(scrapy.Spider):
name = allowed_domains = []
start_urls = []
info = {}
(response):
(response.request.headers)
content_id_search = re.compile()
pic_item_list = response.xpath()
item pic_item_list:
content_name = item.xpath().extract_first()
content_url = + item.xpath().extract_first()
content_id = content_id_search.search(content_url).group()
.info[] = content_name
.info[] = content_id
.info[] = content_url
(.format(content_namecontent_idcontent_url)=)
scrapy.Request(=content_url=.handle_pic_parse)
response.xpath():
now_page = (response.xpath().extract_first())
next_page = % (now_page+)
scrapy.Request(=next_page=.parse)
(response):
pic_nickname_list = response.xpath(
).extract_first()
image_urls = response.xpath().extract_first()
.info[] = pic_nickname_list
.info[] = [image_urls]
(% (pic_nickname_listimage_urls)=)
.infoITEM_PIPELINES = {
: : }TubatuImagePipeline(ImagesPipeline): (resultsiteminfo): image_paths = [x[] okx results ok] image_paths: DropItem() (requestresponse=info=*item=): url = request.url file_name = url.split()[-] file_name
尝试过的解决方式:
程序都無報錯
10
收起
正在回答 回答被采纳积分+1
1回答

精慕门_learner
2022-10-07 06:46:10
# coding:utf-8
import scrapy
import re
# xiaoguotu.to8to.com是域名
# https:// 是协议,当指定域名范围时,写上域名即可
# 为什么图片的链接在网页源代码中没有?网站是通过异步的方式加载的数据,所以源代码中是没有的。
# 模板創建方式: scrapy genspdier 爬蟲名稱 目標域名
class TubatuSpider(scrapy.Spider):
# 爬蟲名稱(name)不能重複, 而不是tubatu.py -會有名稱衝突error
name = 'tubatu'
# 允許爬蟲抓取的域名 -當超過這個起始目錄, 就不會繼續請求
# 防止在爬取过程中,跳到其他网站进行爬取,所以对域名加了限制,不在此允许范围内的域名就会被过滤,而不会进行爬取
# 应将allowed_domains的值设置为xiaoguotu.to8to.com
allowed_domains = ['xiaoguotu.to8to.com']
# 項目啟動後要啟動的文件
start_urls = ['https://xiaoguotu.to8to.com/tuce_sort1?page=1']
info = {}
# Scrapy框架是通过命令控制的,单纯的运行tubatu.py文件并不会执行整个的Scrapy框架
# cmd: scrapy crawl "爬蟲名稱"
# 標黃原因: 由于在TubatuSpider()类中重写parse()方法时,与父类的parse()方法参数不一致导致的
# https://class.imooc.com/course/qadetail/303717
# 默認的解析方法
def parse(self, response):
print(response.request.headers)
# 這裡使用regExp獲取項目id, 需要使用轉譯字符, 轉譯.
content_id_search = re.compile(r'(\d+)\.html')
# pass
# print(response.text)
# response後面可以直接使用xpath方法; response本身就是html object
# 若只是單純使用request, 則需使用lxml.etree實例化成html object
# 每页的第一个是广告,发送异步请求时会报错?
# 第一个class="item" 的div中是没有a标签的,取到的值为None,因此会报错
# 可以使用[position()> 1]忽略第一个元素, 再使用xpath提取即可
pic_item_list = response.xpath('//div[@class="item"][position()>2]')
for item in pic_item_list:
# print(item) -只要對象是selector, 就可以用xpath繼續解析
# 這裡有一個點不要忘了, 表示在當前item下繼續解析
# 通過extract() -return list 或extract_first() -return str, 即可獲取data內容
content_name = item.xpath('.//div/a/text()').extract_first()
# ValueError: Missing scheme in request url: 相关URL必须是一个List,所以遇到该错误只需要将url转换成list即可。
# 項目的url
content_url = 'https:' + item.xpath('.//div/a/@href').extract_first()
content_id = content_id_search.search(content_url).group(1)
self.info['品項名'] = content_name
self.info['品項id'] = content_id
self.info['品項鏈接'] = content_url
print('品項名:{} -- 品項id:{} -- 品項鏈接:{}'.format(content_name, content_id, content_url), end='\n')
# 使用yield發送異步請求
# 使用scrapy.Request()方法 發送請求
# 回調函數 -只寫方法名稱, 不要調用方法
yield scrapy.Request(url=content_url, callback=self.handle_pic_parse)
# break -只獲取一個項目, 而不是whole page
# 頁碼邏輯
if response.xpath('//a[@id="nextpageid"]'):
now_page = int(response.xpath('//div[@class="pages"]/strong/text()').extract_first())
next_page = 'https://xiaoguotu.to8to.com/tuce_sort1?page=%d' % (now_page+1)
yield scrapy.Request(url=next_page, callback=self.parse)
'''
回调函数是一个被作为参数传递的函数
执行A(B)时,调用函数A
函数B作为参数在函数A中调用并执行,称为回调函数
def B():
print('Hello B')
def A(f):
f()
A(B)
'''
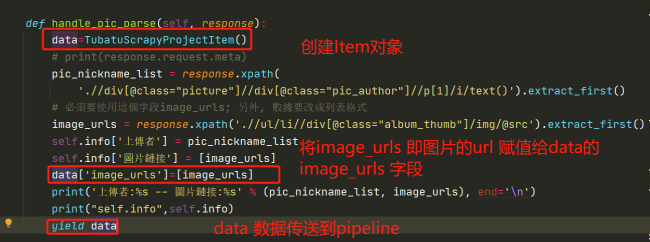
def handle_pic_parse(self, response):
# print(response.request.meta)
pic_nickname_list = response.xpath(
'.//div[@class="picture"]//div[@class="pic_author"]//p[1]/i/text()').extract_first()
# 必須要使用這個字段image_urls; 另外, 數據要改成列表格式
image_urls = response.xpath('.//ul/li//div[@class="album_thumb"]/img/@src').extract_first()
self.info['上傳者'] = pic_nickname_list
self.info['圖片鏈接'] = [image_urls]
print('上傳者:%s -- 圖片鏈接:%s' % (pic_nickname_list, image_urls), end='\n')
yield self.infosettings.py
ITEM_PIPELINES = {
'study_scrapy.pipelines.StudyScrapyPipeline': 300,
'study_scrapy.pipelines.TubatuImagePipeline': 301,
}pipelines.py
# 自定義的圖片下載類需要inherit from ImagesPipeline
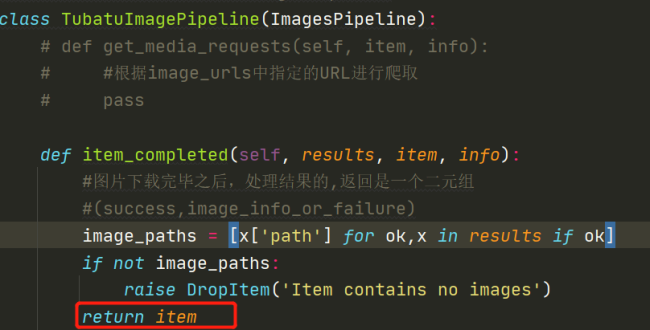
class TubatuImagePipeline(ImagesPipeline):
'''
def get_media_requests(self, item, info):
# 根據image_urls中指定的URL進行爬取
pass
在此直接使用父類方法即可, 不須重寫
'''
def item_completed(self, results, item, info):
# 圖片下載完畢後, 處理結果的, 返回的是一個元組
# 元组的第一个元素为布尔值(Y/N), 第二个元素为一个字典即x,是该item对应的下载结果, 下载失败,即抛出异常DropItem
# (success, {image_info_or_failure})
# 遍历出是否成功的状态和图片信息,如果状态为ok,则取得图片信息中的path
# x是字典类型的数据,可以使用x['path']得到对应的值
image_paths = [x['path'] for ok, x in results if ok]
# results表示下载的结果,返回的是一个列表,其元素是一个元组
# results [(True, {'url':'....', 'path':'...', ..)]
if not image_paths:
raise DropItem('Item contains no images')
pass
def file_path(self, request, response=None, info=None, *, item=None):
# 用於給下載的圖片設置名稱
url = request.url
file_name = url.split('/')[-1]
return file_name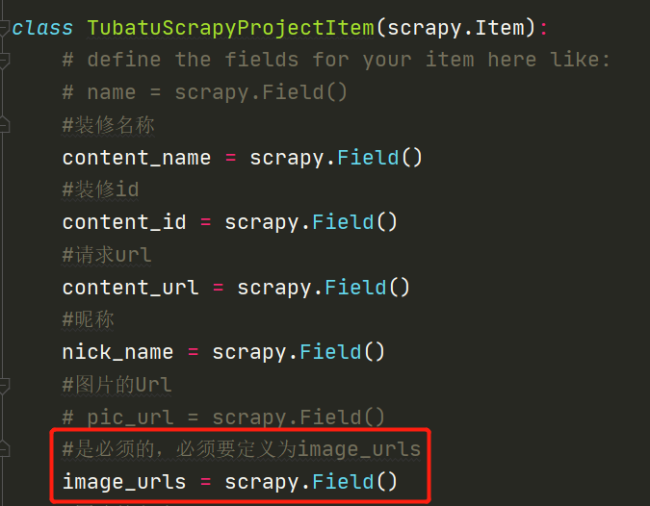
相似问题






登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星