将内层循环封装后效率更高的问题
bobo老师您好,我在练习时发现将选择排序的内层循环封装起来的效率会比不封装的效率快一些,但我想不明白程序运行的逻辑看上去一致,甚至封装后会多一步方法调用的步骤,但是效率反而更快。
麻烦bobo老师指点迷津。
未使用方法封装:
使用方法封装: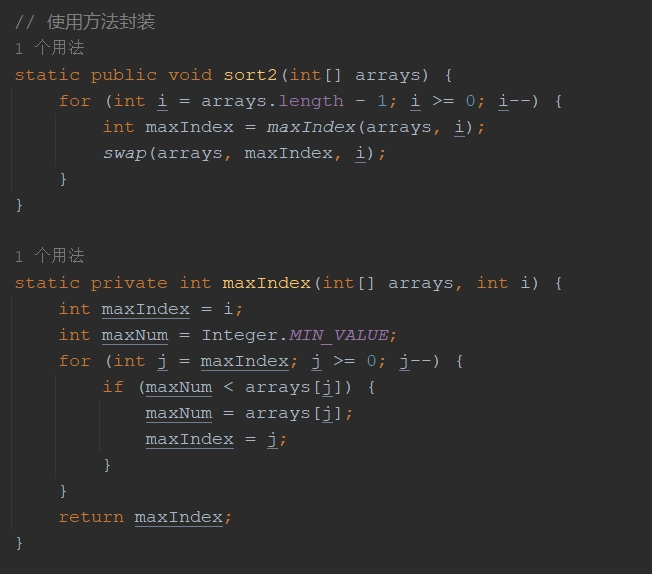
运行结果: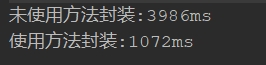
代码如下:
package coding.sorting;
import java.util.ArrayList;
import java.util.List;
public class SortTest {
// 生成长度为n的数组
static List<Integer> gen(int n){
var A = new ArrayList<Integer>();
for(int i = 0; i < n; i++) {
A.add((int) (Math.random() * 10000));
}
return A;
}
// 交换数据的位置
static void swap(int[] A, int i, int j){
int temp = A[i];
A[i] = A[j];
A[j] = temp;
}
// 未使用方法封装
static public void sort1(int[] arrays) {
for (int i = arrays.length - 1; i >= 0; i--) {
int maxIndex = i;
int maxNum = Integer.MIN_VALUE;
for (int j = maxIndex; j >= 0; j--) {
if (maxNum < arrays[j]) {
maxNum = arrays[j];
maxIndex = j;
}
}
swap(arrays, maxIndex, i);
}
}
// 使用方法封装
static public void sort2(int[] arrays) {
for (int i = arrays.length - 1; i >= 0; i--) {
int maxIndex = maxIndex(arrays, i);
swap(arrays, maxIndex, i);
}
}
static private int maxIndex(int[] arrays, int i) {
int maxIndex = i;
int maxNum = Integer.MIN_VALUE;
for (int j = maxIndex; j >= 0; j--) {
if (maxNum < arrays[j]) {
maxNum = arrays[j];
maxIndex = j;
}
}
return maxIndex;
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
var arrays = gen(100000).stream().mapToInt(x->x).toArray();
sort1(arrays);
System.out.println("time usage:" + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
sort2(arrays);
System.out.println("time usage:" + (System.currentTimeMillis() - start));
}
}
正在回答

最大的原因应该是,当把函数封装起来以后,就可以多核执行了。JVM 本身会使用多核做运行时的优化。鉴于你给我的截图二者时间大概是 4 倍差距,我大胆猜测你的电脑应该是 4 核左右的。(或许还有 JVM 其他优化的影响,但我猜这是最重要的原因。)
具体的多核优化到底是如何完成的,已经远超这个课程的范围了,不是一句话两句话能讲清楚的。你可能会有诸如“在还没有调用的时候,应该还不知道这个函数的调用参数,怎么能执行”一类的问题。简答回答就是,系统即使不知道,系统也会尽量去根据历史记录去猜。类似这样的“预测”机制,其实在计算机系统里是非常普遍的,从最底层的 CPU 对指令的执行,到操作系统层面,甚至很多更上层的大型软件系统(或者框架),都有类似的机制。
最典型的就是 “CPU 的分支预测”,通常在体系结构的课程中会介绍这一点,你要是不太了解,可以搜索一下相关关键词。
但不管怎样:
1)这个性能差距是和算法无关的,所以不是我们这个课程关注的重点。实际上,因为这个问题是环境相关的,换一个环境,比如一个单核电脑,或者禁止使用多核权限的环境,都可能改变这个差异。所以,在计算机专业的基础课程中,除非是专门介绍类似环境下的知识的课程,否则都会忽略这类问题的影响。
2)更进一步,可以看到,在当下,一个程序的性能,其实在很多时候,已经完全不是“算法”本身可以决定的了。越是上层的语言,越是如此。这也是在这个课程最初,我说的:不建议使用更“高级”的语言,如 JS,Python,做底层算法学习的原因。语言越高级,和计算机系统底层之间隔的“层级”越多,这种效应越明显。当然,如果仅仅是学习逻辑本身,是没有问题的,但是,如果要考量性能的话,就会遇到类似问题(是其他机制,而非算法本身,在影响性能)。
3)尽管如此,高级算法还是有意义的,并且是非常有意义。你可以在课程后续学到更高级的算法,如归并排序法或者快速排序算法后,再试验一下,就会明白,不管你怎么“调优”你的选择排序的代码,面对更大的数据级别,一个“随随便便”实现出来归并排序法或者快速排序法,都会轻松碾压你“精心调优”的选择排序法。
也正是因为这个原因,在这个课程中,我会不停地强调,我们更关注复杂度级别改变的算法优化。把一个算法从 O(n^2) 优化到 O(nlogn),对性能的改善是巨大的。而一个 O(n^2) 的算法,是否有更好的实现方式?或许有,但是他和语言,环境,硬件体系结构,等等因素相关,而非和“逻辑”本身相关。这些不是我们这个课程关注的重点。
继续加油!:)










恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星