关于Mapreduce这一节数据倾斜剖析的一些疑问
在MapReduce原理剖析这章节中,map阶段第三步:【框架对map函数输出的<k2,v2>进行分区。不同分区中的<k2,v2>由不同的reduce task处理,默认只有1个分区,所以所有的数据都在一个分区,最后只会产生一个reduce task。经过这个步骤之后,数据没什么变化,如果有多个分区的话,需要把这些数据根据分区规则分开,在这里默认只有1个分区。】
【map任务输出的数据到底给哪个reduce使用?这个就需要划分一下,要不然就乱套了。假设有两个reduce,map的输出到底给哪个reduce,如何分配,这是一个问题。这个问题,由分区来完成。map输出的那些数据到底给哪个reduce使用,这个就是分区干的事了。】
对于上面文档中的内容,有两个疑问,到底什么是分区?以及按什么原则来分区?是否就是指 (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks 这个?
关于Mapreduce这一节数据倾斜剖析的问题还有些疑问(条件:1千万条数据,实际占用大概为1.8G,数字为5的数据有910w条)
1、在跑MR任务时,设置reduce任务个数为10个时,有一个reduce耗时为1m26s,这一个reduce的都是数字为5的,正好每个数字占用一个reduce任务吗?
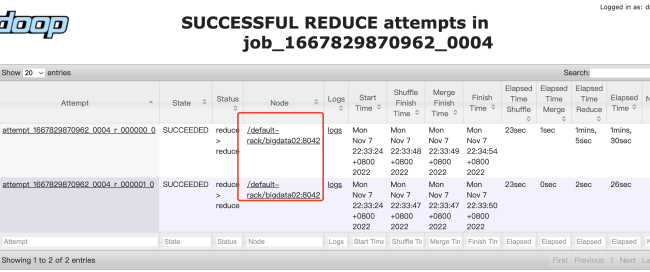
2、如果reduce个数设置为20个甚至100个,因为key只有10个,而只占用10个reduce,其他的都空着吗?我试验了20个reduce任务的情况,最低有2s的,只有一个任务耗时高于10s,最多的那个是1m10s。
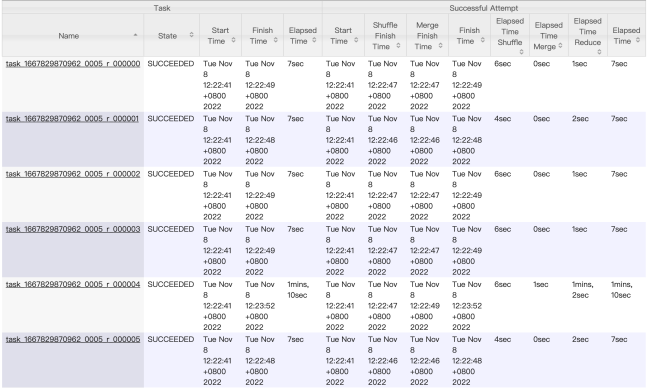
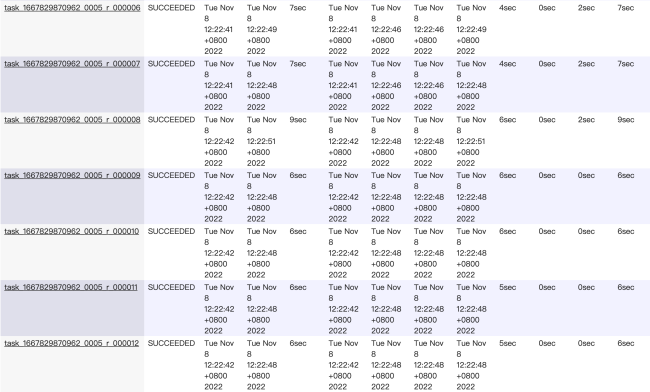
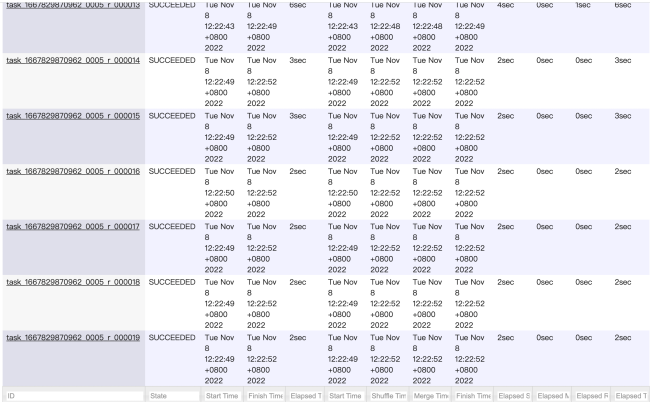
而且查看了hdfs上的输出目录:
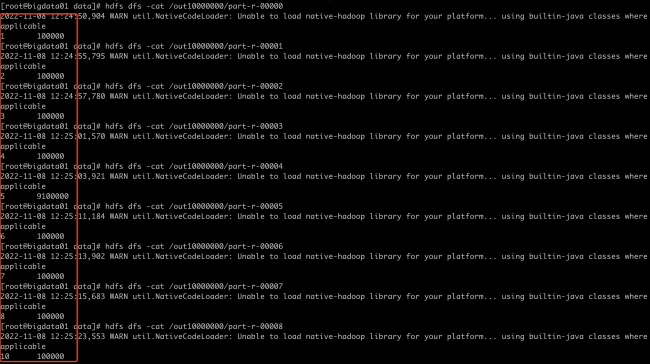
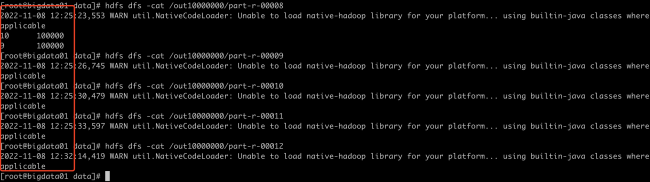
part-r-00009之后的都是空的,是否说明并没有执行reduce任务?如果安排的reduce任务个数多于key的个数,会出现冗余空闲的情况?
3、正常来说是否key和reduce ID应该没有一一对应的关系,只是因为/hello_10000000.dat 中的数据是按1~10的顺序来的,所以导致差不多正好对应上了是吗?另外为何9和10的数字在同一个reduce任务里?使用(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks 公式计算了一下hash值不一样啊
4、如果reduce个数为2个或5个,这10个key又该如何分配reduce任务?试验了2个reduce的情况,最低的reduce任务耗时26s,长的那个1m30s
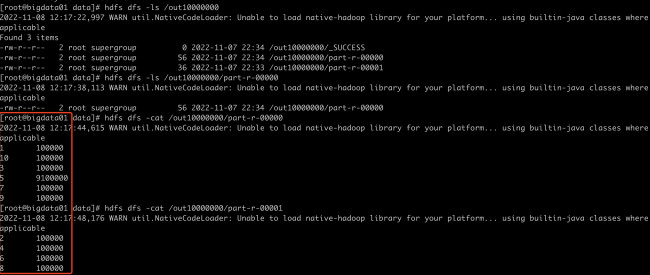
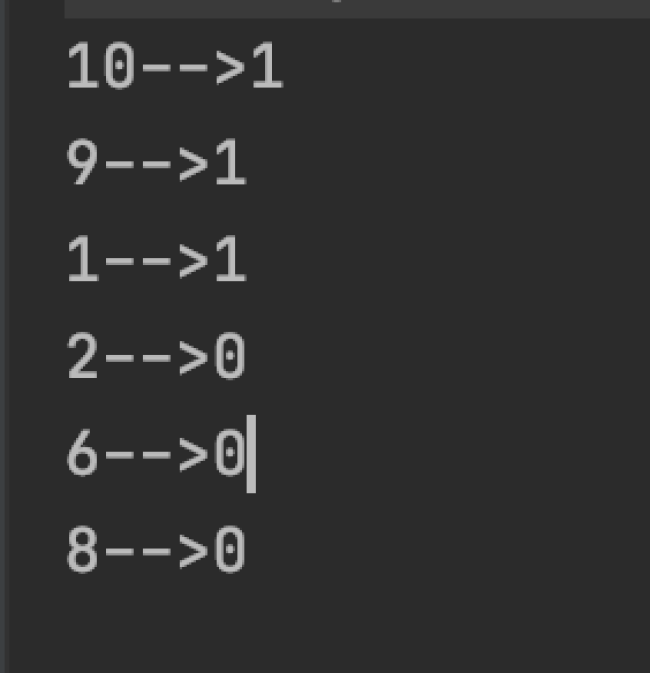
通过计算了key的hash值,初步确认是按这个规则来分区的 。
正在回答

疑问:分区就是按照一定规则把数据分成多个区域,最终不同分区的数据会被不同的reduce task处理。
默认分区是使用的HashPartitioner这个类,核心代码是这个
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
通过上面这个代码可以计算出数据所分配到的分区编号。
1:数字都为5,5作为key,所以相同key的数据会分到一个分区里面,这一个分区对应的就是一个reduce任务。具体哪些key会进入同一个reduce任务,要看这些key返回的分区编号是否是同一个。
2:reduce设置100个,但是数据的key的种类只有10种,那么最多产生10个分区(理论上最多是10个分区,也可能小于10个,具体要看这个计算公式(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks),对应的就是10个reduce任务能处理数据,多余的reduce任务分配不到数据。
3: 数据的key和reduce id没关系,数据先根据key划分到不同分区,每个分区对应一个reduce任务。
9和10的key会进入同一个reduce任务,因为他们计算的分区编号是一样的,都是8。
验证代码是这个:
public class Test {
public static void main(String[] args) {
HashPartitioner<Text, LongWritable> hp = new HashPartitioner<>();
Text text = new Text("10");//key
LongWritable longWritable = new LongWritable(1);
int p = hp.getPartition(text, longWritable, 10);
System.out.println(p);
}
}4:key的分配逻辑同3。












恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星