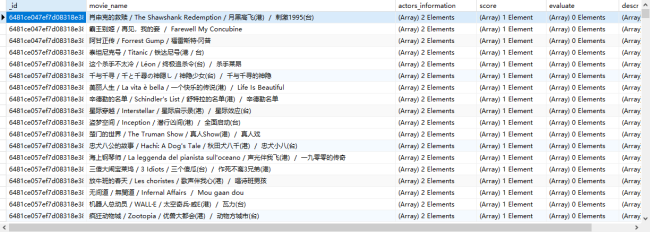
老师,我这是什么问题?怎么解决?
import requests
import pymongo
from queue import Queue
from lxml import etree
import threading
def handle_request(url):
"""
处理request函数
:param url:
:return: response.text
"""
# 自定义请求头
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'movie.douban.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Referer': 'https://movie.douban.com/top250?start=75&filter=',
'Cookie': 'bid=nVbYM3AAU2Q; _pk_id.100001.4cf6=1f6096e2532b9e23.1686192879.; __yadk_uid=fTj7CLY7a3yr6A0Xo85ilS1qYNMc8Y60; ll="118237"; _vwo_uuid_v2=DD681021F84F3560A783E1F7358827029|c0fe785101244962877999214b03ed61; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1686215198%2C%22https%3A%2F%2Fclass.imooc.com%2Flesson%2F2194%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0'
}
response = requests.get(url=url, headers=headers, timeout=10)
# 判断response的状态码是200并且有response满足条件就返回response文本信息
if response.status_code == 200 and response:
return response.text
class PageSpider(threading.Thread):
"""
页码URL请求多线程爬虫类
"""
def __init__(self, thread_name, page_queue, deta_queue):
super(PageSpider, self).__init__()
self.thread_name = thread_name
self.detail_queue = deta_queue
self.page_queue = page_queue
def parse_detail_url(self, content):
html = etree.HTML(content)
data_html = html.xpath("//div[@class='article']/ol/li")
for data in data_html:
self.detail_queue.put(data)
def run(self):
print("{}启动".format(self.thread_name))
try:
while not self.page_queue.empty():
# 从QUEUE中获取数据,并设置为非阻塞状态
page_url = self.page_queue.get(block=False)
# 请求页码链接
page_response = handle_request(url=page_url)
if page_response:
self.parse_detail_url(content=page_response)
except Exception as e:
print("{} run error:{}".format(self.thread_name, e))
print("{}结束".format(self.thread_name))
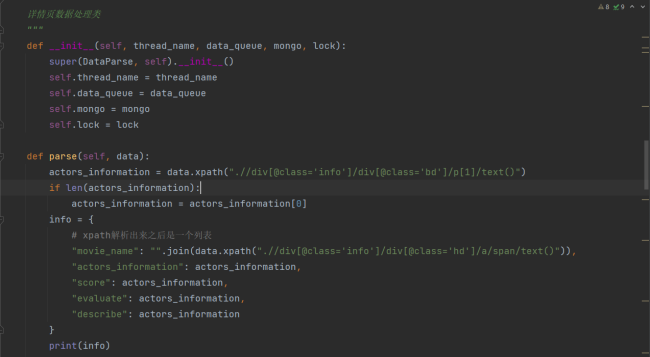
class DataParse(threading.Thread):
"""
详情页数据处理类
"""
def __init__(self, thread_name, data_queue, mongo, lock):
super(DataParse, self).__init__()
self.thread_name = thread_name
self.data_queue = data_queue
self.mongo = mongo
self.lock = lock
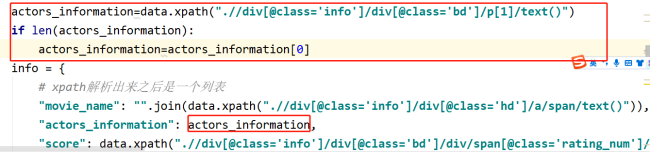
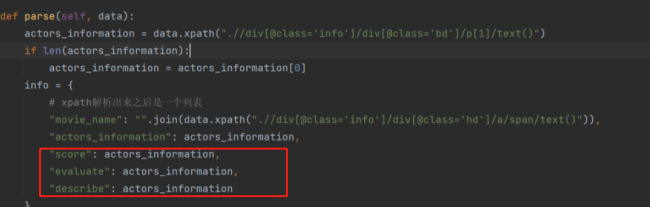
def parse(self, data):
info = {
# xpath解析出来之后是一个列表
"movie_name": "".join(data.xpath(".//div[@class='info']/div[@class='hd']/a/span/text()")),
"actors_information": data.xpath(".//div[@class='info']/div[@class='bd']/p[1]/text()"),
"score": data.xpath(".//div[@class='info']/div[@class='bd']/div/span[@class='rating_num']/text()"),
"evaluate": data.xpath(".//div[@class='info']/div[@class='bd']/div/span[@class='']/text()"),
"describe": data.xpath(".//div[@class='info']/div[@class='bd']/p[2]/span/text()")
}
print(info)
# 由于是多线程并发插入数据,因此使用lock来进行控制
with self.lock:
self.mongo.insert_one(info)
def run(self):
print("{}启动".format(self.thread_name))
try:
while not self.data_queue.empty():
detail_info = self.data_queue.get(block=False)
self.parse(detail_info)
except Exception as e:
print("{} run error:{}".format(self.thread_name, e))
print("{}结束".format(self.thread_name))
def main():
# 页码队列
page_queue = Queue()
# 仅发送3页数据,用于测试
for i in range(0, 226, 25):
page_url = "https://movie.douban.com/top250?start={}".format(i)
# 把页码url放入到队列
page_queue.put(page_url)
# 详情页数据队列
data_queue = Queue()
page_spider_threadname_list = ["列表页采集线程1号", "列表页采集线程2号", "列表页采集线程3号"]
page_spider_list = []
for thread_name in page_spider_threadname_list:
# 实例化创建一个线程
thread = PageSpider(thread_name, page_queue, data_queue)
# 启动线程
thread.start()
# 启动完之后也就是任务处理完之后
page_spider_list.append(thread)
# 查看当前page_queue里面数据状态
while not page_queue.empty():
# 有数据的时候什么都不干 没有数据这个时候就跳出循环了
pass
# 然后释放资源
for thread in page_spider_list:
# 判断当前线程是否存活,存活就阻塞掉
if thread.is_alive():
thread.join()
# 使用Lock,要向mongo插入数据
lock = threading.Lock()
myclient = pymongo.MongoClient(host='127.0.0.1', port=27017,
username='admin', password='abc123456')
mydb = myclient["db_movies"]
mycollection = mydb["movie_info"]
# 启动多线程,处理数据
data_parse_threadname_list = ["数据处理线程1号", "数据处理线程2号", "数据处理线程3号", "数据处理线程4号", "数据处理线程5号"]
data_parse_list = []
# 启动了5个线程处理详情页的信息
for thread_name in data_parse_threadname_list:
thread = DataParse(thread_name, data_queue, mycollection, lock)
# 启动线程
thread.start()
data_parse_list.append(thread)
# 查看当前data_queue里面数据状态
while not data_queue.empty():
# 有数据的时候什么都不干
pass
# 数据为空就释放资源
for thread in data_parse_list:
# 判断线程是否存活,存活就阻塞
if thread.is_alive():
thread.join()
if __name__ == '__main__':
main()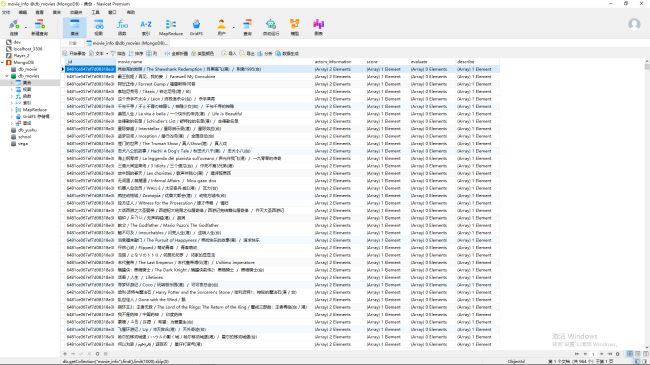
11
收起
正在回答 回答被采纳积分+1
1回答

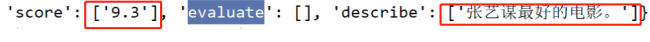
相似问题
这个问题怎么解决呀
30
0
5




为什么我这个是错的,老师写的就是对的呢?
73
0
5






老师,SDK会有版本问题,怎么解决
7
0
5


老师,我的网页404是为什么?
11
0
4


请问老师,这个报错怎么解决呢?
8
0
5






登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程











恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星