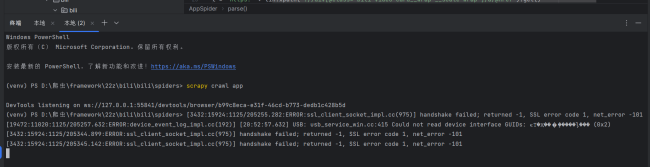
老师,为什么会一直显示握手失败啊,而且代码也没有运行下去
import scrapy
from ..items import BiliItem
import time
from scrapy_redis.spiders import RedisSpider
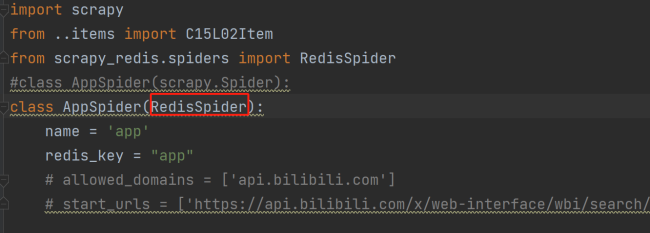
class AppSpider(scrapy.Spider):
name = "app"
redis_key = 'app'
# allowed_domains = ["www.bilibili.com"]
# start_urls = ["https://search.bilibili.com/all?vt=18668812&keyword=python&from_source=webtop_search&spm_id_from=333.1007&search_source=5"]
page = 30
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(AppSpider, self).__init__(*args, **kwargs)
def parse(self, response):
time.sleep(5)
try:
link = response.xpath('//div[@class="video-list row"]/div')
for lin in link:
lin_url = 'https:' + lin.xpath('.//div[@class="bili-video-card__wrap __scale-wrap"]/a/@href').get()
yield scrapy.Request(url=lin_url, callback=self.lin_parse, dont_filter=True)
new_url = f"https://search.bilibili.com/all?keyword=python&from_source=webtop_search&spm_id_from=333.1007&search_source=5&page=11&o={self.page}"
print(new_url)
self.page += 30
print(self.page)
yield scrapy.Request(url=new_url, callback=self.parse, dont_filter=True)
print('进行翻页')
except :
print('end')
def lin_parse(self, response):
item = BiliItem()
item['dianzhan'] = response.xpath('//div[@class="video-like video-toolbar-left-item"]/span/text()').get()
item['toubi'] = response.xpath('//div[@class="video-coin video-toolbar-left-item"]/span/text()').get()
item['shouchang'] = response.xpath('//div[@class="video-fav video-toolbar-left-item"]/span/text()').get()
item['zhuanfa'] = response.xpath('//div[@class="video-share"]/span/text()').get()
yield item
# bili-video-card__wrap __scale-wrap
# bili-video-card__wrap __scale-wrap
# bili-video-card__wrap __scale-wrap
# 详情页
# https://www.bilibili.com/video/BV19a411k7fw/?spm_id_from=333.337.search-card.all.click&vd_source=01d1cc167d01b5a7cfe6be617b3d6c6e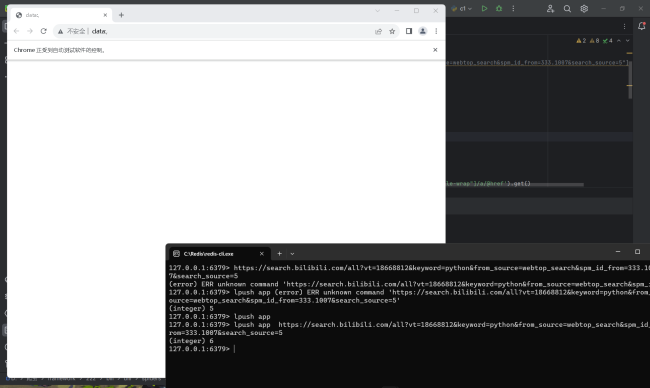
BOT_NAME = "bili"
SPIDER_MODULES = ["bili.spiders"]
NEWSPIDER_MODULE = "bili.spiders"
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
#SPIDER_MIDDLEWARES = {
# "bili.middlewares.BiliSpiderMiddleware": 543,
#}
DOWNLOADER_MIDDLEWARES = {
"bili.middlewares.BiliDownloaderMiddleware": 543,
}
ITEM_PIPELINES = {
"bili.pipelines.BiliPipeline": 300,
'scrapy_redis.pipelines.RedisPipeline': 400
}
DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
SCHEDULER_PERSIST = True
REDIS_URL = 'redis://127.0.0.1:6379'
DOWNLOAD_DELAY = 1# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class BiliItem(scrapy.Item): dianzhan = scrapy.Field() toubi = scrapy.Field() shouchang = scrapy.Field() zhuanfa = scrapy.Field() pass
import time
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
class BiliDownloaderMiddleware:
# 启动浏览器,初始化cookies
def __init__(self):
self.sevice = Service(executable_path="D:/爬虫驱动/chromedriver.exe")
self.driver = webdriver.Chrome(service=self.sevice)
self.cookies = {}
# 如果cookies为空,那么发送请求获取cookies
def process_request(self, request, spider):
if self.cookies == {}:
self.driver.get('https://www.bilibili.com/')
self.driver.maximize_window()
time.sleep(1)
# 获取首页cookie
cookies = self.driver.get_cookies()
# 提取想要的cookie值
dick = {cookie['name']: cookie['value'] for cookie in cookies}
self.cookies = dick
# print(self.cookies)
time.sleep(1)
self.driver.quit()
# 如果cookies不等于空,那就加到request的cookies里面
# 等于空就获取一遍
request.cookies = self.cookies
return None# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class BiliPipeline:
def process_item(self, item, spider):
data = {
'dianzhan': item['dianzhan'],
'toubi': item['toubi'],
'shouchang': item['shouchang'],
'zhuanfa': item['zhuanfa']
}
print(data)
return item23
收起
正在回答 回答被采纳积分+1

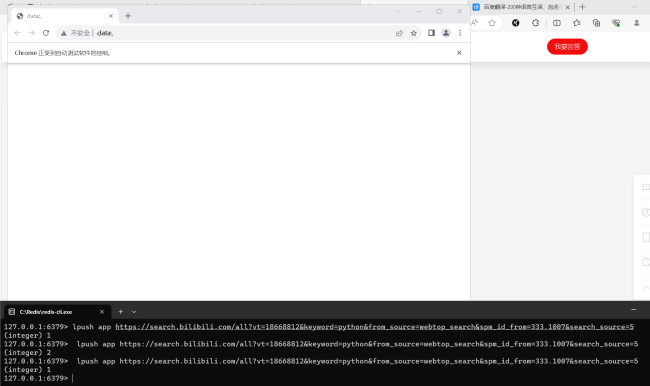
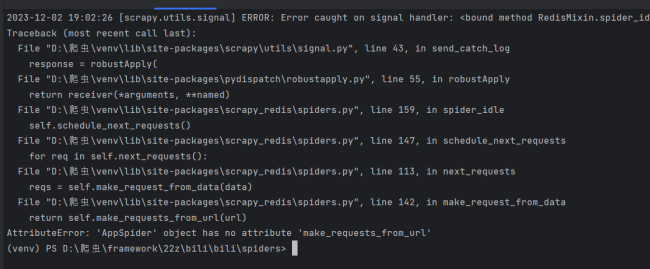
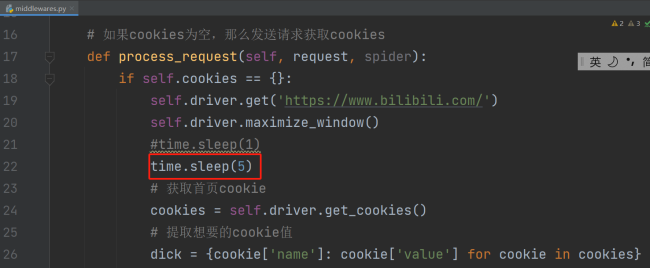
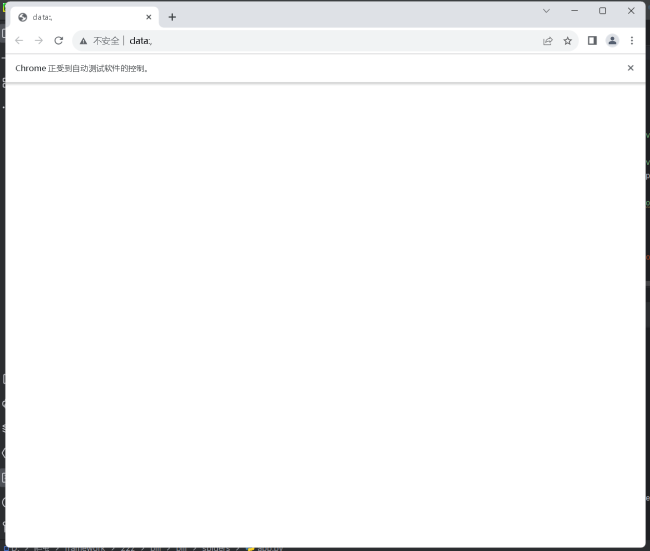 老师,我修改代码之后还是跟之前一样。我运行代码之后获取cookie那个步骤好像出问题了,页面就一直卡在这没有动过
老师,我修改代码之后还是跟之前一样。我运行代码之后获取cookie那个步骤好像出问题了,页面就一直卡在这没有动过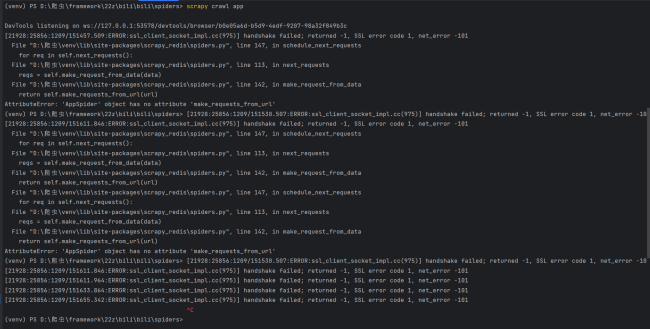
相似问题







登录后可查看更多问答,登录/注册















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星