增加排序的算子后,出现异常
老师,我在任务程序里增加了排序的算子后,出现了had a not serializable result: org.apache.kafka.clients.consumer.ConsumerRecord,即ConsumerRecord无法序列化异常。根据网上的提示,在sparkConf中增加了如下属性配置项后,异常消失
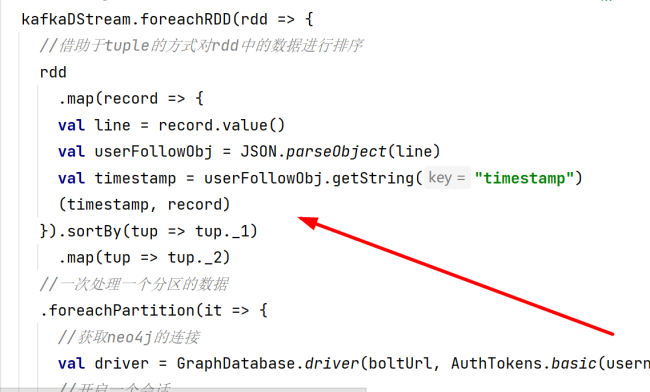
new SparkConf().set("spark.serializer", classOf[KryoSerializer].getName)虽然这个问题解决了,但是我很困惑为什么我增加了如下排序算子后,就必须要增加这个配置项,否则会报错。而没有增加排序算子,即用老师的原方案,不增加这个配置项也不会报错。而且我发现一个现象,通过我这种方式增加排序算子后,控制台信息中rdd好像是4个4个的增加;而在没有增加排序算子之前,则是1个1个的rdd增加。这是什么原因呢?其中的原理是什么呢?是我的这个排序方式有问题吗?老师会怎么写这个排序方案呢?
7
收起
正在回答
1回答

1:因为sortby这个算子中的数据需要是可序列化的,但是他目前操作的ConsumerRecord默认是无法序列化的,所以需要添加spark.serializer配置项。也可以在sortby之前把ConsumerRecord转化一下,转化成可以序列化的数据类型,其实后面需要的是line,也就是record.value(),所以rdd.map返回(tmestamp,line)即可。
2:控制台中rdd几个几个的增加,都是正常的,没有什么必然联系。可能是在foreachPartition之前增加了一些算子,导致数据处理的慢了,所以积压的数据就多了,这样输出的时候就一起输出了。也可能和控制台输出程序在某些时刻的打印速度有关系。
3:针对rdd内的数据排序,常规思路就是使用sortby。
相似问题








登录后可查看更多问答,登录/注册






恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星