老师,使用您课上的方法无法获取信息。输入您视频里面的请求URL就可以获取,不知道我哪一步有问题
登陆购买课程后可参与讨论,去登陆吧
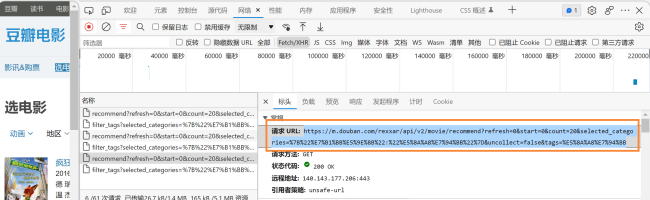
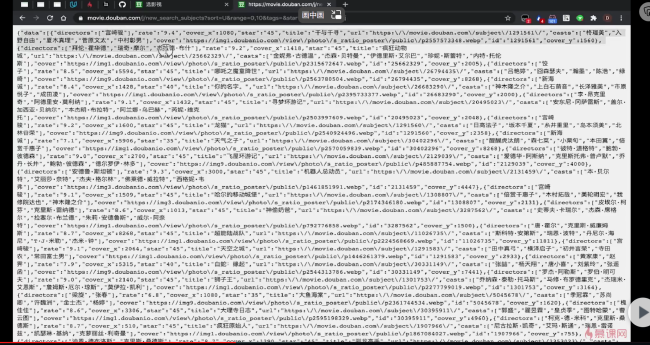
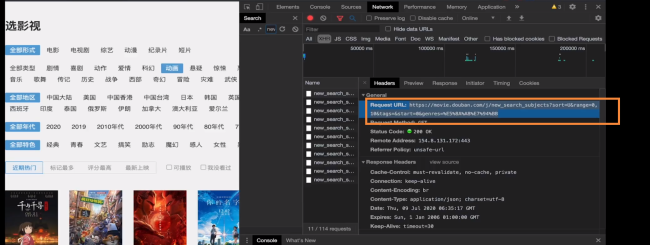
没太明白你的问题?爬虫获取数据的核心是URL,简单的网站而言,网站通过抓取网站url加模拟数据获取(比如点击下一页)就能获取数据,但由于现在的网站都有反爬机制,也就是会通过限制你登陆、爬取数据的频次和时间,增加验证码等方式禁止爬虫,尤其是一些电商类网站难度会高一些。所以这个获取数据的url,我们通常要扒出来,也就是我们要尽可能获取直接返回数据结果的url,你要知道前端页面都是通过html渲染包装数据呈现出来的,所以你说用上课的方法没有获取到,是不是因为你没有找到获取数据结果的那个url?
恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
登录后可查看更多问答,登录/注册
从0开始学数据分析,互联网各岗位的标配技能,产品经理、运营经理、技术人员人人必备、能学会的实用技能。
26 5
27 1
71 3
56 2
165 52
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号
在线咨询
领取优惠
免费试听
领取大纲

















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星