使用百度千帆存储摘要历史记录时报错
问题描述:
老师,我在使用ConversationSummaryBufferMemory时用的百度千帆模型,在保存历史信息时报这个错误:Can't load tokenizer for 'gpt2',不知道是什么情况
相关截图:
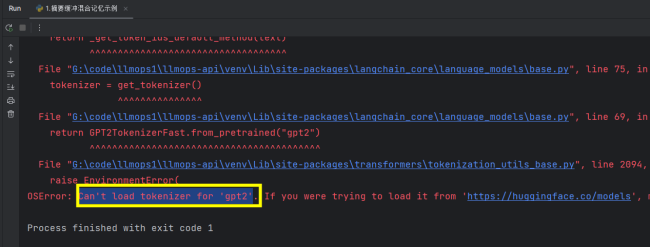
35
收起
正在回答
1回答

这是因为tiktoken并没有针对所有的大语言模型都配置了词表,在LLM的底层_get_encoding_model()找不到对应的词表导致的错误,如果想解决这个问题,可以重写下_get_encoding_model()这个方法,例如:
def _get_encoding_model(self) -> Tuple[str, tiktoken.Encoding]: model = "cl100k_base" encoding = tiktoken.get_encoding(model) return model, encoding
这样就可以解决问题啦(本质上是LangChain封装不完善+很多LLM没有提供词表导致的bug)~
和您这边另外一个问题是同个原因,上面的函数使用了cl100k_base这个词表,以解决LangChain对于国产LLM没有预设词表的问题。
相似问题




登录后可查看更多问答,登录/注册
AI Agent 全栈开发工程师
- 参与学习 706 人
- 解答问题 493 个
全流程打造你自己的(Coze/Dify)低代码智能体开发平台;2025年入行正当时,企业急需,人才稀缺,竞争小;无论入行还是转行,首选口碑好课,门槛低、成长高
了解课程




恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星