关于在Spark SQL命令行中集成Hive
问题描述:
老师,
1、我为求快跳过了修改log4j的步骤,进入spark sql命令行后出现这些warn提示应该不影响吧?(spark sql命令行中能正常创建、查询表等)
2、接着我在hive命令行执行insert语句插入一条数据,然后卡住了,这是为什么呢?(此时hive这边计算引擎用的不是spark吗,之前用mapreduce虽然慢但是没卡住)
相关截图:
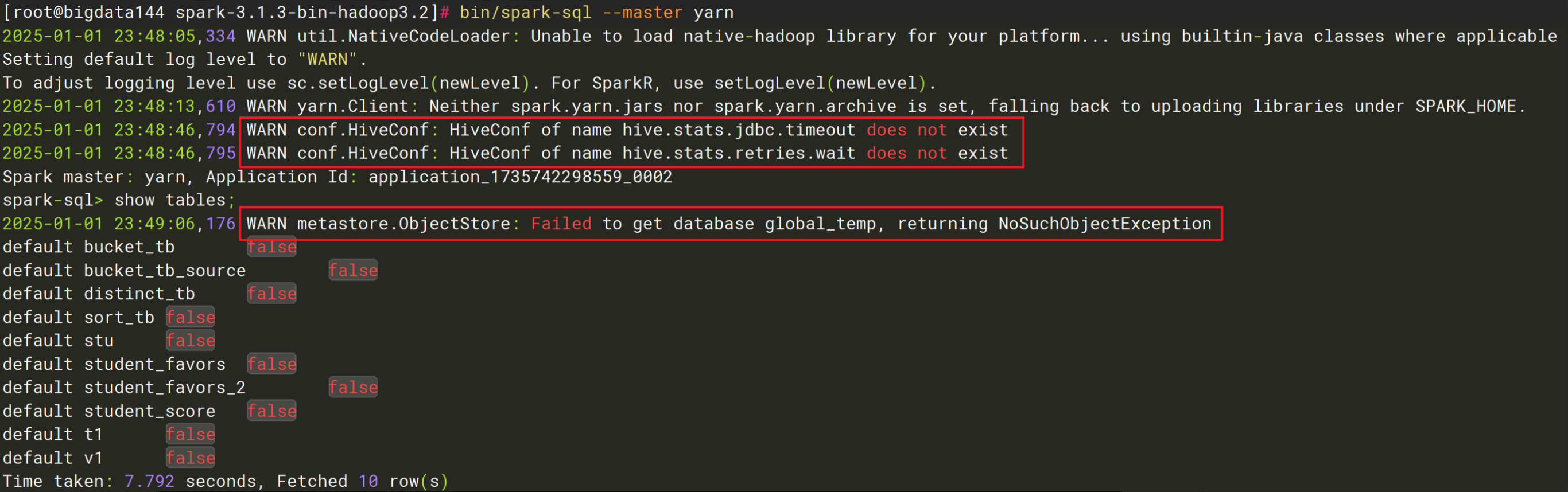
4
收起
正在回答
1回答

1.不影响,就是看上去日志有点多,比较乱
2.需要到yarn上看一下,看看对应的spark任务为什么没有执行
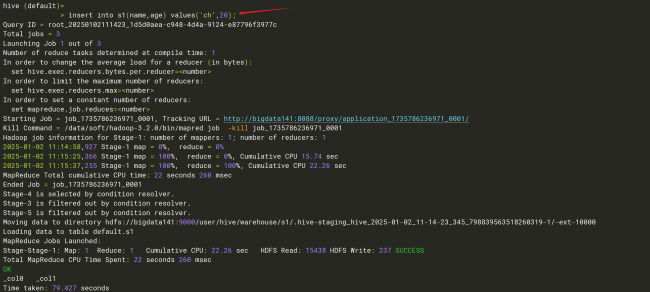
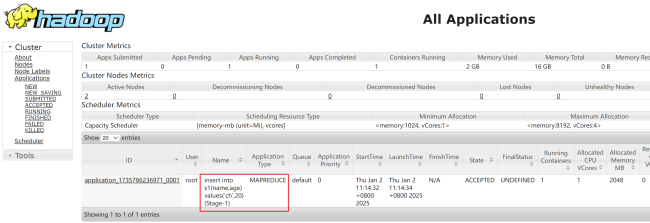
相似问题
登录后可查看更多问答,登录/注册








恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星