亲爱的同学们,经过本阶段的学习,相信大家已掌握编写简单爬虫的相关知识,现在让我们亲自动手运用所学知识来完成下面的作业吧!
题目要求:
根据所学知识,动手实践抓取豆瓣电影TOP250中前250条经典电影的相关信息,结合浏览器的开发者模式分析目标站点URL结构、规律和目标抓取数据的网页结构、定位等,运用xpath和正则表达式实现数据提取和封装,最后将数据保存至MongoDB数据库。
数据抓取过程中应当注意以下三点:
(1)目标站点首页url: https://movie.douban.com/top250
(2)抓取的目标信息包含项如下:电影名称信息(movie_name)、电影演职人员信 息(actors_information)、电影评分数值(score)、评价数信息(evaluate)、电影简 述信息(describe)、来源URL信息(from_url)
(3)编码时请运用面向对象思想及封装特性优化代码结构
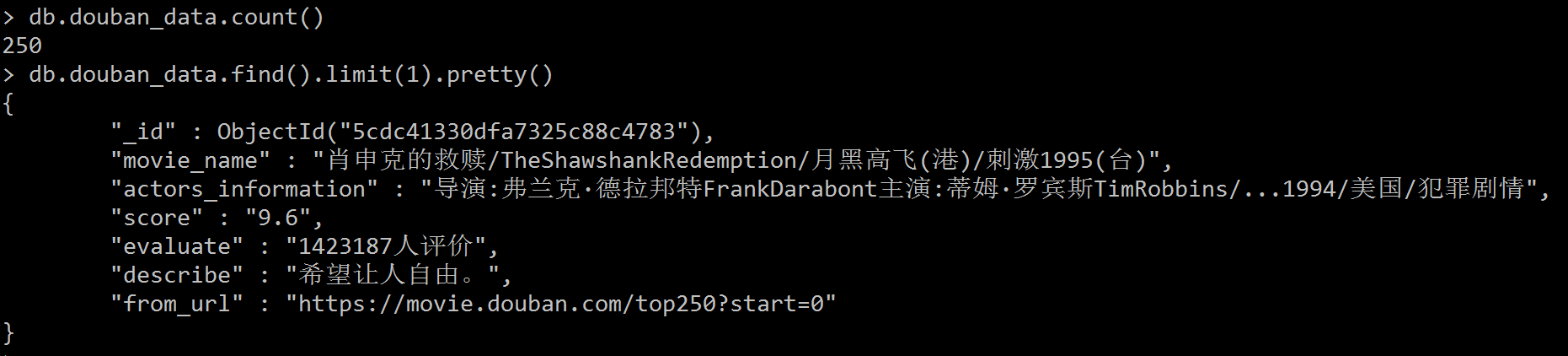
运行效果:
一、语言和环境
- 版本
Python3.6或Python3.6以上版本 - 开发工具
Pycharm
二、程序整体要求
1、 划分功能模块,根据题目要求设置不同的类,在类中实现相应功能的管理。
2、 类的标识要清楚易懂,代码结构要层次分明,代码编辑思路要清晰、整洁。
3、 要求Python代码书写、命名符合规范,在代码中添加必要的注释
4、 最终抓取数据效果与提供的页面效果图、结构 保持一致,文字大小、背景色也不做统一要求
5、 将作业项目形成压缩文件并提交
三、思路分析
由题目要求和运行效果,可以分析出项目中可以抽取两大模块: crawl_douban_movie_info_top250.py爬虫文件和handle_mongo.py存储数据文 件
前者主要实现网络爬虫中的数据抓取与解析的业务逻辑:
-
爬虫类(HandleDoubanMovieTop250,继承自object):
<1>设定初始化方法,并设置实例变量header、page_url(list类型)分别记录爬虫的请求头和目标抓取页的url
<2>设定实例方法handle_page_url(),将构造好的目标页URL存储于记录目标抓取页url的列表中
<3>设定实例方法handle_request(),传递目标页url参数,发送爬虫请求, 返回爬取的文本类型数据
<4>设定实例方法handle_page_detail(),传递目标页url参数,解析当前页的返回数据,通过xpath和正则表达式解析题目要求第2项中需要抓取的目标信息,并调用数据存储类实例douban_mongo进行数据存储
<5>设定实例方法run(),通过线程池方式启动爬虫 -
设置程序入口函数main(),创建HandleDoubanMovieTop250类的实例douban,并启动爬虫
-
调用程序入口函数以运行程序
后者主要完成相应的数据存储,最终数据存储如效果图所示:
-
数据存储类(Handle_Mongo,继承自object):
<1>自定义初始化方法,连接MongoDB并创建名为douban的数据库
<2>自定义实例方法handle_save_data()实现数据存储,接收item(dict类型)参数,定义表名如douban_data,通过insert方法插入最终数据 -
创建Handle_Mongo类的实例,命名为douban_mongo
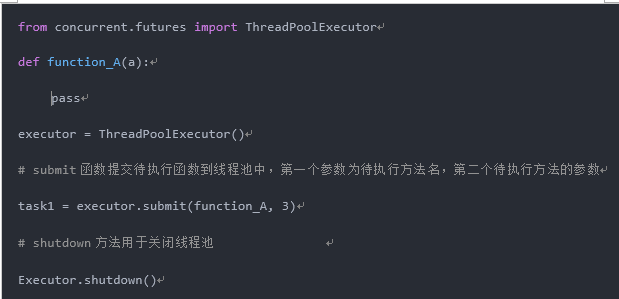
注:关于线程池基本用法请参考如下代码:
1.规范【10分】
(1)作业所涉及的类都封装在独立的 ".py"文件中
(2)类的定义、类的成员变量命名规范 代码结构要层次分明
(3)Python代码规范整洁并添加适量注释
2.程序整体运行效果【10分】
程序正常运行效果,且满足效果图要求
3.爬虫项目分析【30分】
(1)正确的使用浏览器的开发者模式,提取出请求头
(2)正确查找、分析出页码页的生成规则
4.爬虫文件【40分】
(1)成功请求豆瓣电影页码页
(2)正确的使用xpath和正则表达式
(3)正确的利用线程池加快抓取速度
(4)正确的解析题目中要求的字段
5.数据存储文件【10分】
能够调用pymongo模块,最终实现数据入库