亲爱的同学们,经过本阶段的学习,相信大家已经掌握网络爬虫的常用技术,能够应用多线程进行简单爬虫项目的开发,现在让我们亲自动手运用所学知识来完成下面的作业吧!
打开豆瓣电影 Top 250,网站url:https://movie.douban.com/top250
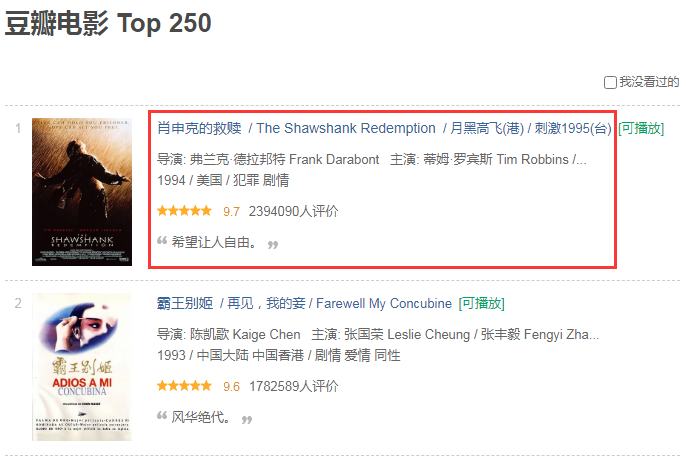
作业描述
根据所学知识,抓取250条经典电影的相关信息,要求如下:
1、抓取内容包含:电影名称、演职人员、电影评分、评价人数、电影简述信息
2、将数据存入本地文件a.txt中
3、运用多线程实现数据的抓取和存储
思路分析
1、分析页面URL
第1页,url地址是https://movie.douban.com/top250?start=0
第2页,url地址是https://movie.douban.com/top250?start=25
第10页,url地址是https://movie.douban.com/top250?start=225
由此可以看出,页码变量从0开始,步长为25,最后一页的页码是225,通过range()函数可以构造出页码变量,并将url放入页码队列中
# 通过range构造页码变量,从0开始,到226结束,步长为25
for i in range(0, 226, 25):
url = "https://movie.douban.com/top250?start={}".format(i)
2、定义handle_request函数,处理页面URL请求
豆瓣影视Top250请求头如下:
header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Host": "movie.douban.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
3、定义页码URL请求多线程爬虫类
启动多线程,从页码队列中读取数据,请求页码链接,获取页面的电影信息,并将电影信息放入数据队列中
4、定义电影数据处理类
启动多线程,从数据队列中获取电影数据,解析电影名称、演职人员、电影评分、评价人数、电影简述信息,并存入到本地文件中。
评分标准是什么?
- 规范【15分】
1)文件、类、成员变量命名规范;
2)代码结构层次分明;
3)符合Python代码规范,核心代码有必要的注释。 - 程序整体运行效果【15分】
程序正常运行,且满足效果图要求 - 实现多线程请求页面【35分】
(1)成功请求豆瓣电影页码页
(2)将页面的电影信息写入到数据队列中 - 实现多线程处理电影数据【35分】
(1)正确解析电影名称、演职人员、电影评分、评价人数、电影简述信息
(2)数据成功写入到本地文件a.txt中