Flink批处理无法产生结果
问题描述:
程序运行后,一直处于运行中,无法得出结果。
尝试过的解决方式:
之前一直是akka超时错误,增加配置后不出现akka超时错误,但是无法出结果。
增加程序运行配置:-Xms1024m -Xmx1024m 还是无法出结果
相关截图:
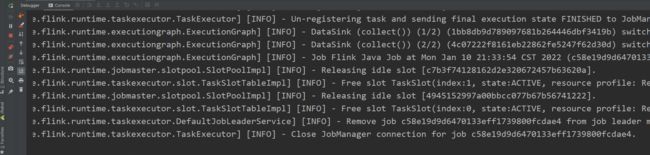
相关代码:
package com.bigdata.fink.batch.transformation
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
import scala.collection.mutable.ListBuffer
/**
* mapPartition算子使用:一次处理一个分区
*/
object BatchMapPartitionScala {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
//设置超时时间;akka是flink实现client,jobManager,TaskManager之间的网络通信.
//单位 毫秒
env.getJavaEnv.getConfiguration.setInteger("akka.ask.timeout",3000000)
//单位:毫秒
env.getJavaEnv.getConfiguration.setInteger("web.timeout",3000000)
// conf.setInteger("web.timeout",300000)
import org.apache.flink.api.scala._
val text = env.fromCollection(Array("hello you","hello me","hello the"))
text.map(s=>s)
.setParallelism(2)
.mapPartition(it=>{
var list = ListBuffer[String]()
//可以在此处创建数据库连接,建议把这块代码放到try-catch
//注意:此时是每个分区获取一个数据库连接,不需要每处理一条数据就获取一次连接,性能较高
it.foreach(line=>{
val words = line.split(" ")
for(word <- words){
list.append(word)
}
})
list
//关闭数据库连接
}).print()
//注意:针对DataSetAPI,如果在后面调用的是count、collect、print,则最后不需要指定execute即可。
// env.execute("BatchMapPartitionScala")
}
}9
收起
正在回答 回答被采纳积分+1
1回答

相似问题
老师,这里所说的批量处理,无法获取id
24
0
3


关于mybatis批处理的问题
3
0
3


发生死锁的原因
36
2
4


生产者和消费者模型,为什么代码正常运行,却无法结束?
25
0
3


关于选择题的代码异常处理顺序
9
0
5
登录后可查看更多问答,登录/注册









恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星