基础薄弱,经验欠缺,难以理解大数据
复杂的运算机制和运行原理
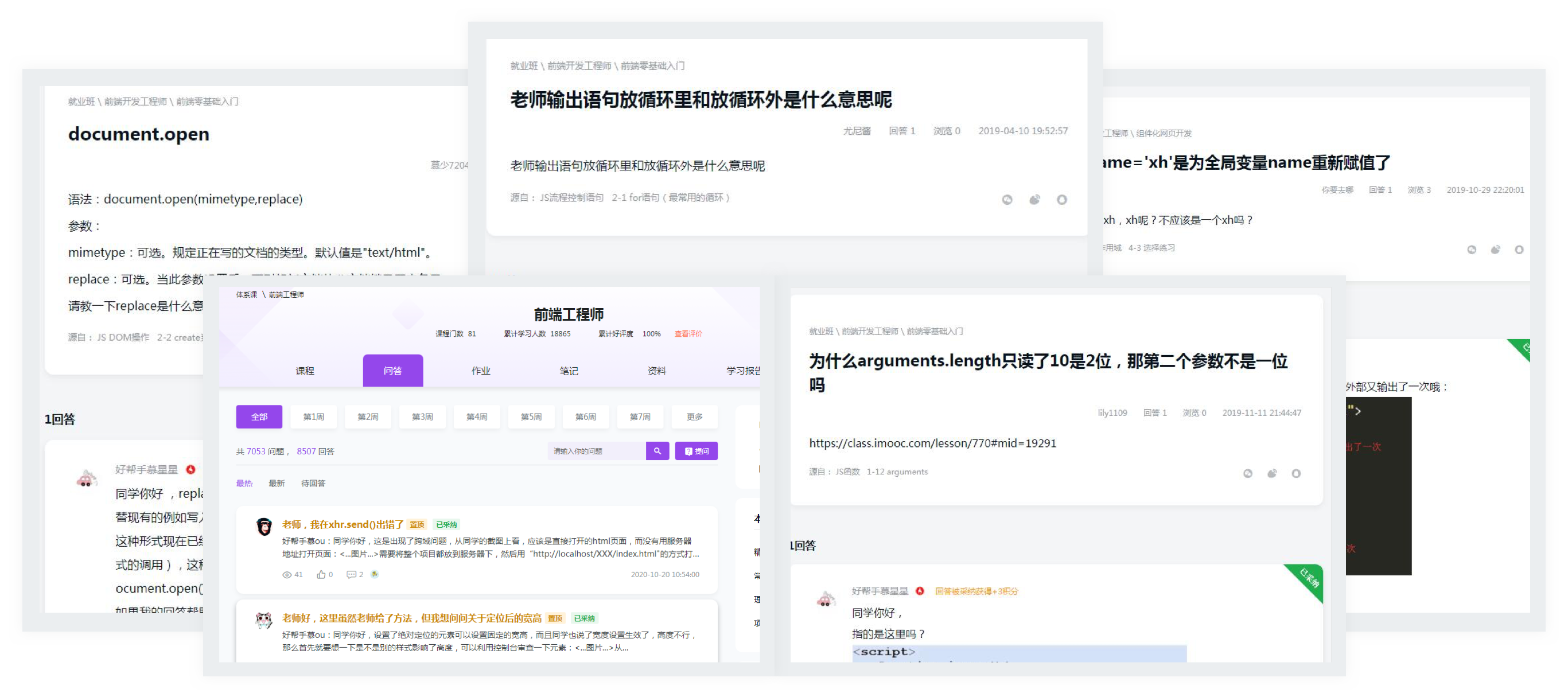
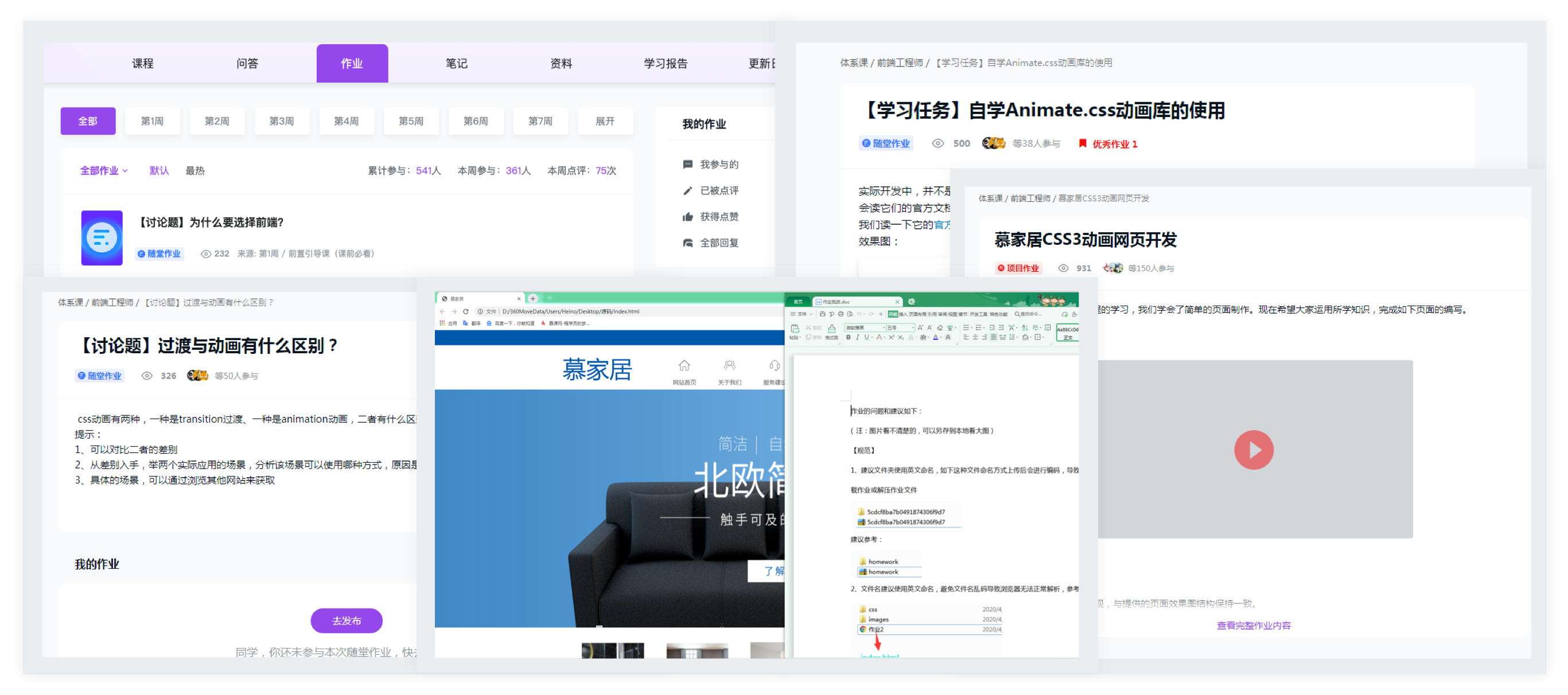
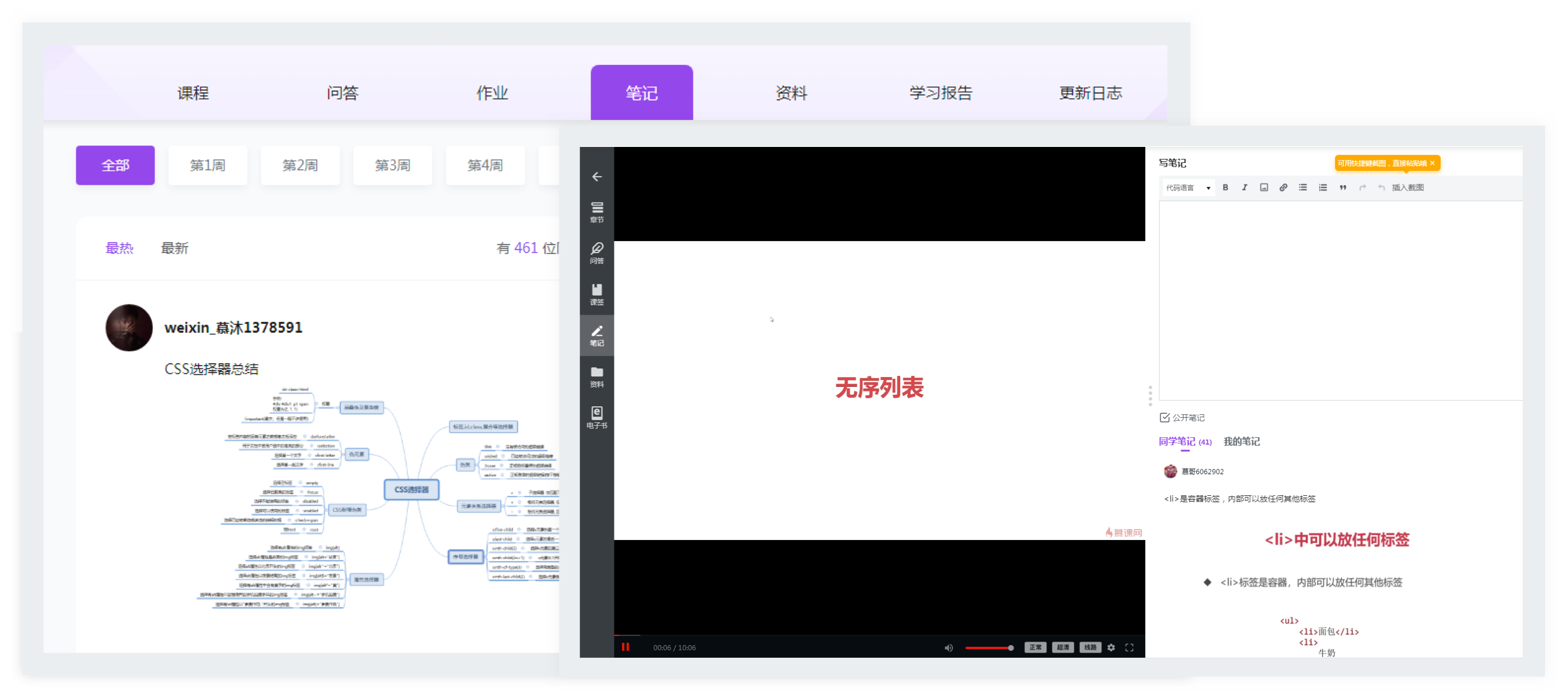
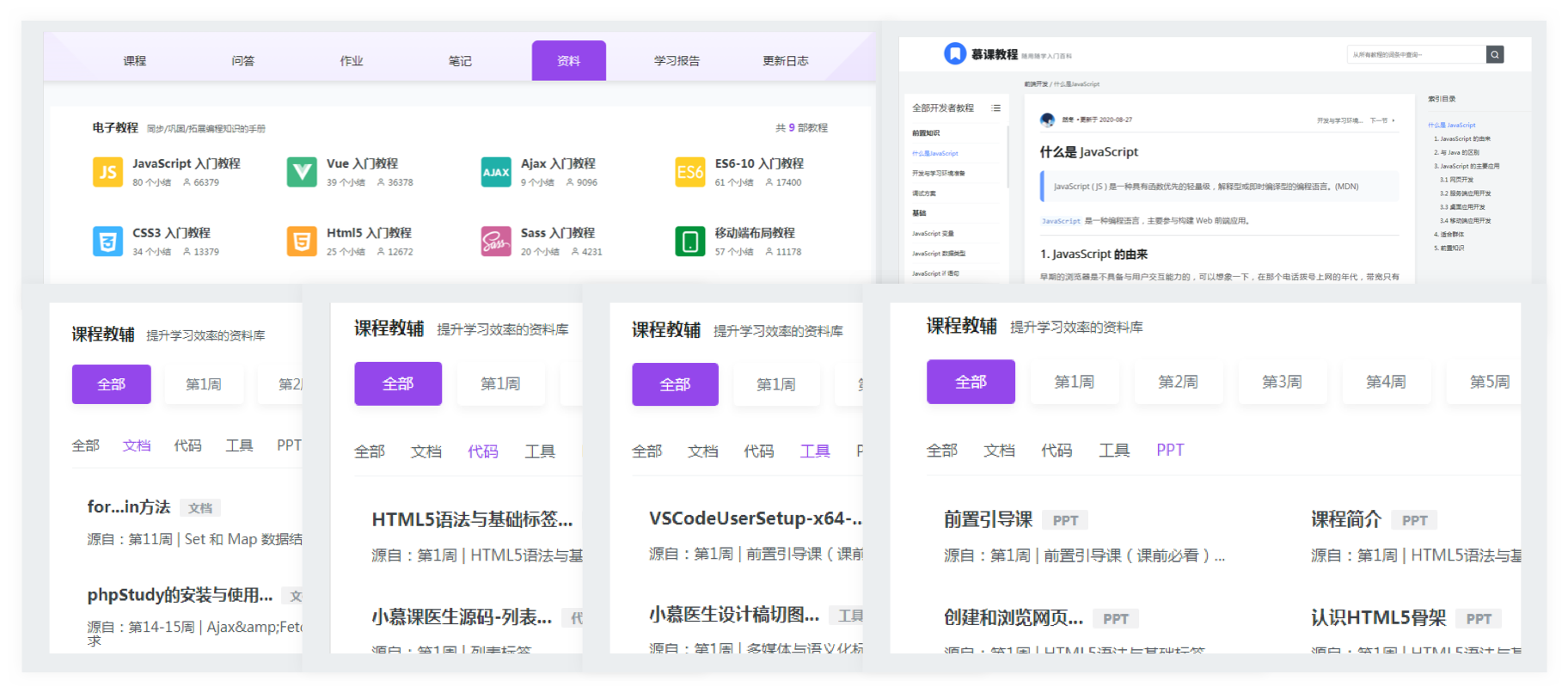
项目简介:
整合各个业务线数据,为各个业务系统提
供统一&规范的数据出口。是整个大数据
系统中的关键,是所有数据分析、数据挖
掘等工作的基础。
供统一&规范的数据出口。是整个大数据
系统中的关键,是所有数据分析、数据挖
掘等工作的基础。
项目性能满足日增100T+数据处理;查询
速度满足秒级查询。
速度满足秒级查询。
项目收获:
学习并掌握数据仓库的分层设计&数据仓
库从0~1的构建过程。
库从0~1的构建过程。