Scrapy爬取去哪儿的问题
import scrapy
class QunarsSpider(scrapy.Spider):
name = 'qunars'
allowed_domains = ['qunar.com']
start_urls = ['http://qunar.com/']
def start_requests(self):
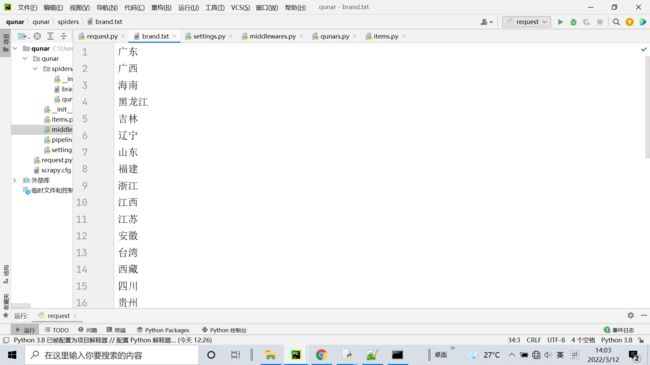
with open('brand.txt','r',encoding='utf-8') as f:
brand_data = f.read().split('\n')
for data in brand_data:
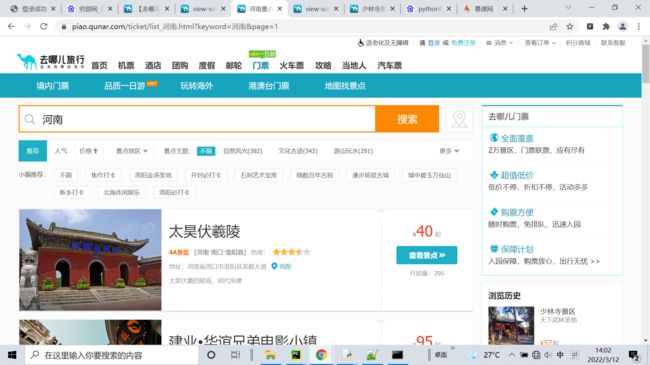
url = 'https://piao.qunar.com/ticket/list_{}.html?keyword={}&page=1'.format(data,data)
yield scrapy.Request(url=url,callback=self.parse)
break
def parse(self, response):
print(response.text)# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class QunarSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class QunarDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class HandleDetail(object):
def process_request(self,spider,request):
list = 'QN1=000084002eb43e5d5998a297; _i=ueHd8pgEXG-9hvgyUkKSPPh5r_kX; QN57=16455529528490.6390322655416552; QN269=99553F01940911ECB6DBFA163E349AFD; fid=aebb14b4-5f6f-47b0-a865-3bda874bf3e0; QN300=s%3Dbaidu; QN99=2156; QunarGlobal=10.68.76.61_5de71223_17f7c54acd4_-6a6e|1647058696993; qunar-assist={%22version%22:%2220211215173359.925%22%2C%22show%22:false%2C%22audio%22:false%2C%22speed%22:%22middle%22%2C%22zomm%22:1%2C%22cursor%22:false%2C%22pointer%22:false%2C%22bigtext%22:false%2C%22overead%22:false%2C%22readscreen%22:false%2C%22theme%22:%22default%22}; QN205=s%3Dbaidu; QN277=s%3Dbaidu; csrfToken=oQmdTacWDUB2bVhUvQiZlSw7cIIK3q64; QN601=89ff82f76685304f3eb3ba9baffa9b61; QN48=000090802f103f1528488bc3; QN163=0; Hm_lvt_15577700f8ecddb1a927813c81166ade=1645552953,1647058709; ariaDefaultTheme=null; QN67=11390%2C12638%2C14709%2C32468; QN63=%E6%B2%B3%E5%8D%97%7C%E5%B9%BF%E4%B8%9C; QN71="MzkuMTYyLjEzMi4xNTU66aaZ5rivOjE="; _vi=fstSc6PS33wO8I-Tm40JQLZ2tAzrimHDwhsUfvVVQ-A0mQI9mdZ8ETimxNpySIKz9pw0RhMgmBDfn2EafuXVK7ZWYb_kBSJJ1iemaGxzmTtZGviXOC0KchyM5C7_tDJIchsmXiNAsQcuV_60sLWEmBDoQyCTrre_e19vOiajdFQQ; Hm_lpvt_15577700f8ecddb1a927813c81166ade=1647064572; __qt=v1%7CVTJGc2RHVmtYMSswTWwrTGNMT2U2QzVUV29IdEVvMFZ4YjF4MGFmOXBuRGxZazYyY1Jtc2libjQyTllHOVJXR1RHTHU1dkpUajJqZ1Bua1lIN3VxSlpDOXM5S212SW1KZGZCd2FDOEVJK2JUSHBzdkV2UTlrNnVPcUFVb1c1L1ZLRlhNOTN0SW5NR2VTZzkvM1JGWFRPcWhUbDRpL1RtNGxDRFgvVGh2NTQ4PQ%3D%3D%7C1647064572048%7CVTJGc2RHVmtYMS9QM3VKY3FaakVrOW1kS0NYRlJienRseFRsanVBMkFkekRqcWYrc0hXRWZ0WUNhdkhRVFphS3MxVkdNQnhKTWZzLzRGK3RUUVFHTmc9PQ%3D%3D%7CVTJGc2RHVmtYMTg2c0tUWHJsSUZObHJiM3owaWRzNWR3VHR1SUgxMDNPZ2dsY0pVR21DOGJGeXJET0pjY1BBY2E0VW1FNUM2RW5aTTFBUEc1cDZXc2s1dTFwMVJIRTZNUlFoWVNuTDFTeW55a3JXdFZsQnVQNWg4WTR5NGhjaC9va2pad2x5VTNDNlVyZWNVQ1ErRWMzNjdUQ0VnUFdrcTcreElHRGY1Q0hldGNzVDBRakNGb1dheXBrd00rSHdDRlFjSGg5ZWNlWmd5SzZwZk1ENHlaWmVpRDF5ZkVhaWlzK1ZRNWNLcTdJSjlua1VkVCs0NnY0V1p1cndpMG5FN09US3c4Z3F0MlJiZ0FSeGVhUkx4SEdkY3BkaC9oV1k1a0ZOeVFIaVB6TTNpcjRvS2FPc29PcTlmUnkwcWFFdXM3enBlV0R2Z3R0NGJHQktCajRvN3JTM0tObTUxUFFobm9KanFHR1BEQTJuZHE1RGttczFCbUV4UmdidzJtdDhrRm95M0FZMkNiS010ZWZ4OHVjdGZwUm04a0hqa2kxT3Vrc042U09NN0NQT3hNM0VHeXNwTENPNVV0WDVtZU9WUTFZWjR3Q3luUllCVTFnaC8xTm0vQVFUQlBPaEthL2syZytHZS9VbGFBUldlTGUyTFJScGlsbWE0NHBDR0RGbTZLSUxqNkdJN1lReWVzLy9udzhYSStRcEhmc2FKRFpRVEQ3dDFZUVRNZ1RaSCs5SzRXNTFwRm1tTUZmRUV4YVBjWmZnSXYzZGJLcFhvMkw4OEVnalFJd01keEdFZk9HVThFOU5DV1FaQkVBRDh3bTdUc29ZRzZYR3FTdStJYVdJUDhVR1VTNWJYOFg5S0luak1IV0NoOVA1QTVieXhOZGYweHAxcWVKUVFNVlVHQjN0RnI2empIc243YVl0a05rQ1liTE55eldGM00wdDAvaDcvRHBuS1FzdTVQd3VGSXNFSEw0WFNQSGJDVjF6NkEvd0Njb0s4NzMrMXYvNWtJQVNGUDBUM3pqQ0FxUHpudXpPaWh3SEpQT2x6QS9DQWY1TDN4L2g1TnhaK2VFdXFTMkVTRWJQTk94RUdkWU01OHJLYw%3D%3D; QN271=dc1e1120-b3a7-4ddd-9a98-da0116c7e4df; JSESSIONID=25C6F8FB59C620267156E5C340120EA9; QN267=1693476361ac63f8f; QN58=1647063016419%7C1647064575194%7C7'
dict = {i.split("=")[0]: i.split("=")[-1] for i in list.split(';')}
request.cookies = dict
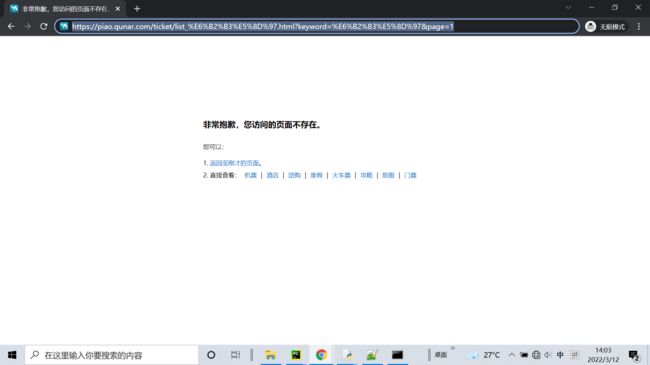
return request请求不到源码,打开无痕浏览404
20
收起
正在回答 回答被采纳积分+1
相似问题
关于scrapy的异步问题,谢谢老师
21
0
3


关于爬虫爬取数据的问题
14
0
3


关于过滤的问题
11
0
3
scrapy爬取数据不完整
32
0
5


scrapy-redis分布式爬取
5
0
1


登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16436 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星