关于爬虫爬取数据的问题
爬虫代码
import scrapy
import os
class TianSpider(scrapy.Spider):
name = 'tian'
allowed_domains = ['tianqi.com']
#start_urls = ['http://lishi.tianqi.com/zhengzhou/index.html']
def start_requests(self):
with open(os.path.join(os.getcwd(),'spiders','brand.txt'),'r',encoding='utf-8') as f:
all_data = f.read().split('\n')
for data in all_data:
url = 'http://lishi.tianqi.com/{}/index.html'.format(data.split(',')[0])
yield scrapy.Request(url=url,callback=self.parse,meta={'item':data.split(',')[1]})
def parse(self, response):
all_url = response.xpath("//div[@class='linegraphborder']/div/div[4]//a/@href")
for data in all_url:
new_url = 'http://lishi.tianqi.com'+data.extract()
yield scrapy.Request(url=new_url,callback=self.page_parse,meta={'item':response.meta['item']})
def page_parse(self,response):
all_data = response.xpath("//ul[@class='thrui']/li")
for data in all_data:
item = {}
item['城市'] = response.meta['item']
item['日期'] = data.xpath("./div[1]/text()").extract_first()[:10]
item['最高气温'] = data.xpath("./div[2]/text()").extract_first().replace('℃','')
item['最低气温'] = data.xpath("./div[3]/text()").extract_first().replace('℃','')
item['天气'] = data.xpath("./div[4]/text()").extract_first()
item['风向'] = data.xpath("./div[5]/text()").extract_first()[-2]
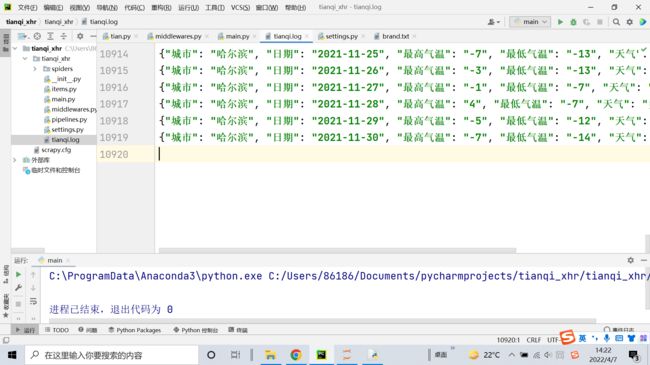
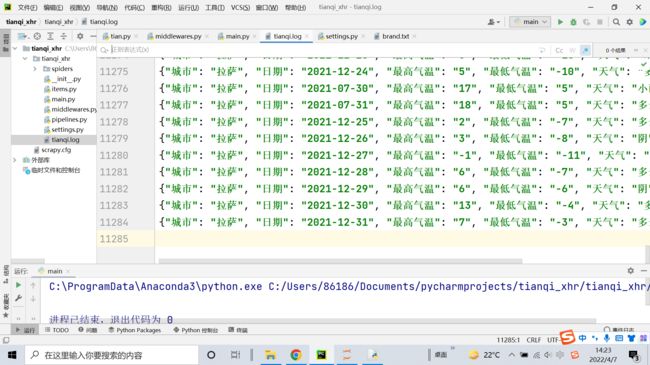
yield item老师为什么没次爬取数据量不一样,总是缺失数据
14
收起
正在回答 回答被采纳积分+1
1回答

相似问题



登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星