数据爬取问题
懂球帝页面进行改版后所有的文章均放在动态标签页下,链接为https://www.dongqiudi.com/articles,经过分析后发现其中的文章会在后面添加一串数字,请问如何在爬虫程序中构造url?还有就是抓取url,发表时间和图片信息该如何编写xpath?请老师解答
44
收起
正在回答
1回答

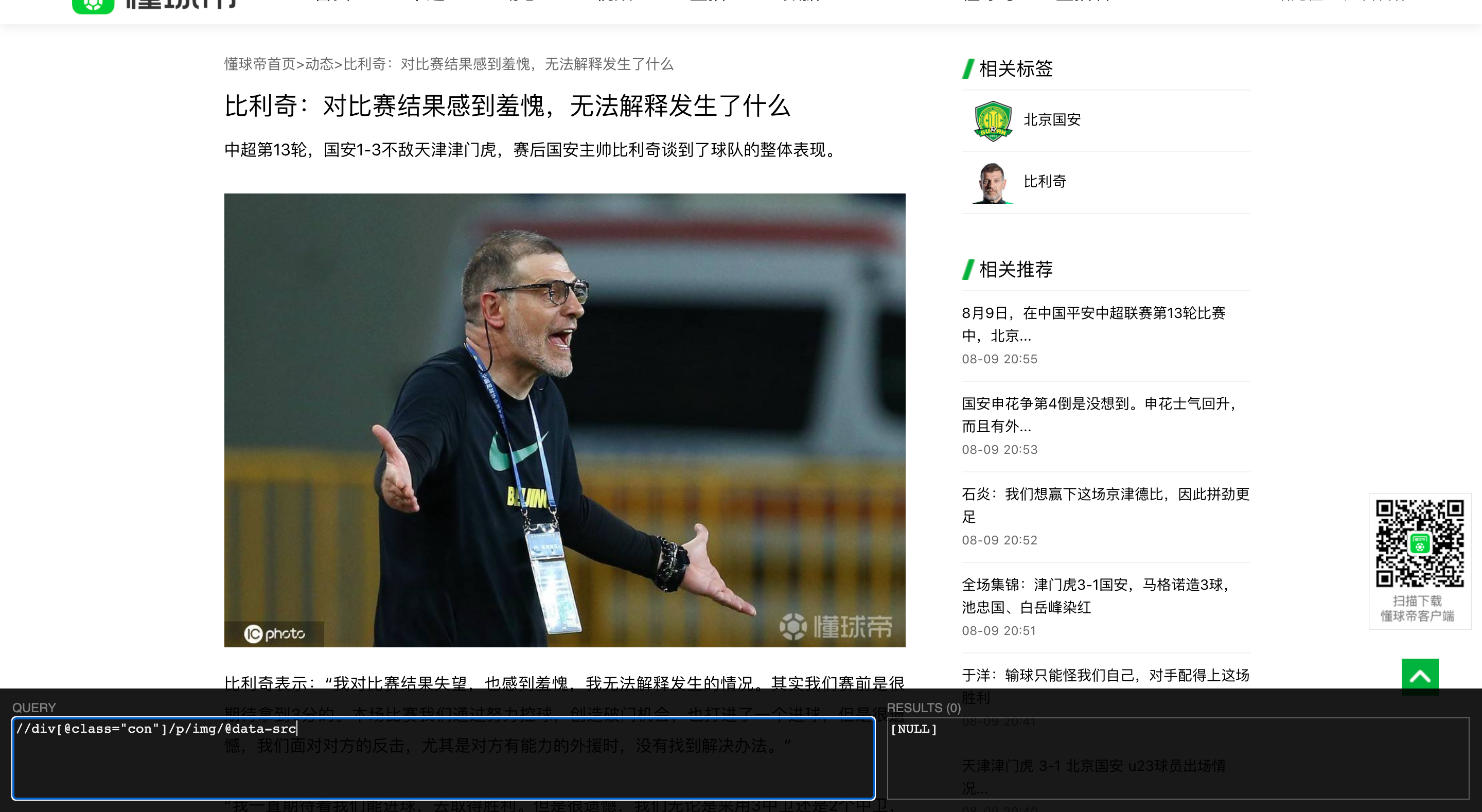
同学,你好!
1、打开懂球帝网站后,先在首页打开浏览器的'检查',选择NetWork---->Fetch/XHR,再点击动态标签,可以看到返回的json文件

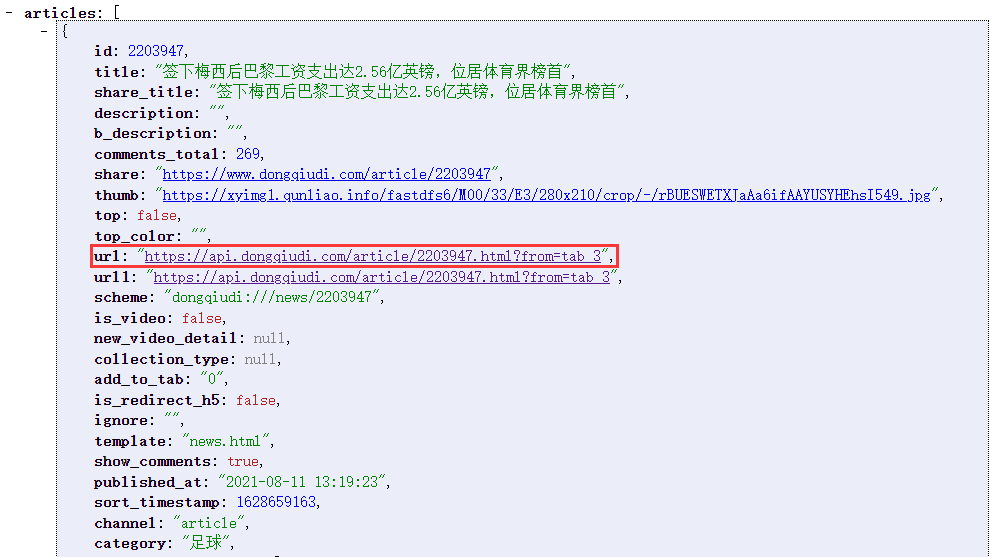
2、打开其中一个json文件,可以看到是英超,next是下一页数据的url,articles是页面中的每个文章

根据next可以分析出请求的url

3、articles中的url是当前文章的url,published_at是发表时间

在处理页码请求返回的数据时,可以使用json.loads()解析数据后使用for循环得到每个具体的文章,再使用get获取相应的数据

在解析详情页数据时,url和发表时间直接使用response.request.meta[]取值即可

4、图片可以直接获取图片的url


祝学习愉快!
相似问题
关于爬虫爬取数据的问题
14
0
3


scrapy爬取数据不完整
32
0
5


main()中文本处理线程代码 的 位置问题
18
0
4


数据抓取不全的问题
16
0
3

老师我把page写的好大,还是能获取到数据
8
0
3


登录后可查看更多问答,登录/注册
4.入门主流框架Scrapy与爬虫项目实战
- 参与学习 人
- 提交作业 107 份
- 解答问题 1672 个
Python最广为人知的应用就是爬虫了,有趣且酷的爬虫技能并没有那么遥远,本阶段带你学会利用主流Scrapy框架完成爬取招聘网站和二手车网站的项目实战。
了解课程







恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星