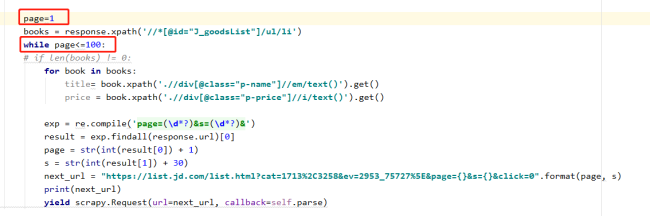
老师我把page写的好大,还是能获取到数据
import scrapy
class AppSpider(scrapy.Spider):
name = "app"
allowed_domains = ["search.jd.com"]
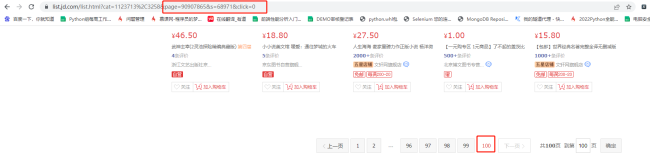
start_urls = ["https://list.jd.com/list.html?cat=1123713%2C3258&page=90907865&s=68971&click=0"]
def parse(self, response):
lis = response.xpath('//*[@id="J_goodsList"]/ul/li')
nac = response.xpath('//*[@id="J_bottomPage"]/span[1]/a/em/text()')
bq = response.xpath('//*[@id="J_goodsList"]/ul/li[38]/div/div[6]/a/text()')
print(lis)
# for i in lis:
# title = i.xpath('.//div/div[3]/a/em/text()').get()
# price = i.xpath('.//div/div[2]/strong/i/text()').get()
# print(title, price)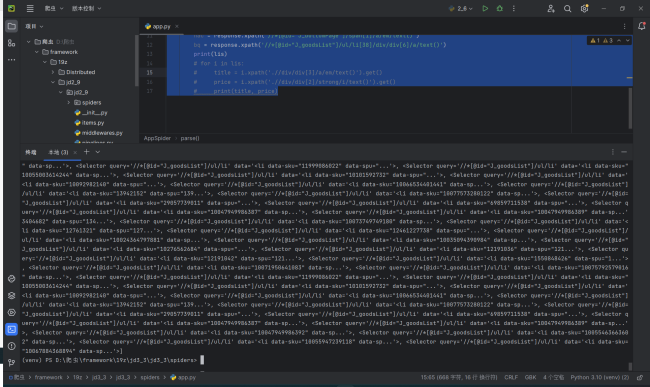
8
收起
正在回答 回答被采纳积分+1
1回答






















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星