不知道为什么出错了
import scrapy
from ..items import C07Item
class AppSpider(scrapy.Spider):
name = "app"
allowed_domains = ["book.douban.com"]
start_urls = ["https://book.douban.com/latest"]
def parse(self, response):
# 先获取每一个书籍的li
# print(response.text)
whole = response.xpath('//ul[@class="chart-dashed-list"]/li')
# 然后通过循环获取每一个书籍的详情页链接
for i in whole:
link = i.xpath('.//h2/a/@href').get()
# 从新发送请求,url是详情页链接,执行自定义函数,效果是获取书名和出版社
yield scrapy.Request(url=link, callback=self.parse_data)
# 定义下一页链接数据
next_url = response.xpath('//*[@id="content"]/div/div[1]/div[4]/span[4]/a/@href').get()
# 如果下一数据不是空那就执行一下数据,为空就不执行
if next_url is not None:
# 定义下一个的链接 urljoin这个函数能把阔后内的数据跟最顶上的目标url拼接在一起,
next_url = response.urljoin(next_url)
print(next_url)
# 发送请求 链接为下一页的链接,函数是解析函数,继续获取下一页的数据
yield scrapy.Request(url=next_url, callback=self.parse)
# 出现else是因为目标网址第一页的下一页xpath位置跟第二页不一样
else:
next_url = response.xpath('//*[@id="content"]/div/div[1]/div[4]/span[3]/a/@href').get()
next_url = response.urljoin(next_url)
print(next_url)
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_data(self, response):
itme = C07Item()
itme['title'] = response.xpath('//*[@id="wrapper"]/h1/span/text()').get()
itme['press'] = response.xpath('//*[@id="info"]/a[1]/text()').get()
yield itme# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymongo
class C07Pipeline:
def __init__(self):
self.clint = pymongo.MongoClient("mongodb://localhost:27017")
self.db = self.clint['douban']
self.col = self.db['qwe']
def process_item(self, item, spider):
res = self.col.insert_one(dict(item))
# print(res)
return item
def __del__(self):
print("End")# Scrapy settings for c07 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "c07"
SPIDER_MODULES = ["c07.spiders"]
NEWSPIDER_MODULE = "c07.spiders"
LOG_LEVEL = "ERROR"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.51"
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
"c07.middlewares.C07SpiderMiddleware": 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "c07.middlewares.C07DownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"c07.pipelines.C07Pipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class C07Item(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() press = scrapy.Field()
27
收起
正在回答 回答被采纳积分+1

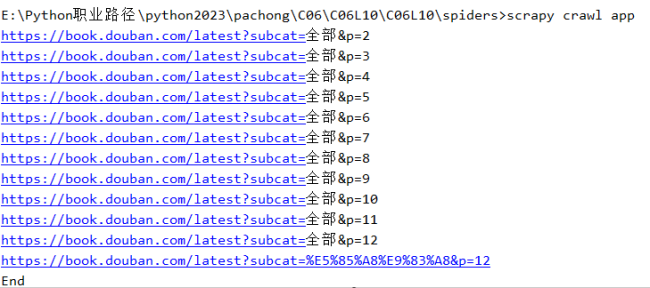
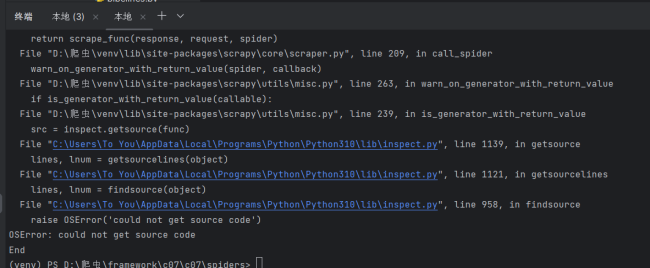 无法获取原代码
无法获取原代码相似问题







登录后可查看更多问答,登录/注册















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星