问题
在课程中3:55老师关于存入redis中key的讲解不是很明白
为什么在命名redis_key = 'jingdong'之后,存入redis的数据的键值依然是name = 'app'中的app
10
收起
正在回答
1回答

同学,你好!配置 redis_key 可以将不同的爬虫任务分配到不同的任务队列中,同学可以理解redis_key 就是放第一次开始爬取的url。在 Scrapy-Redis 中,爬取后的数据保存在 Redis 中时,通常遵循<spider_name>:items的格式进行命名的。 其中:
<spider_name> 是具体的爬虫名称,这样可以确保不同爬虫的数据被分开存储。
items 是默认的存储键,用于存储爬取的数据。
之前爬取flask 项目时老师存储redis里的数据也是app ,指的是name="app"中的app
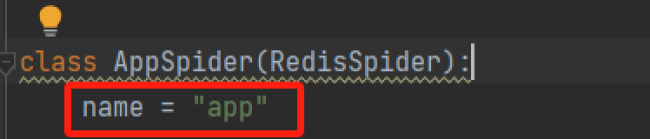
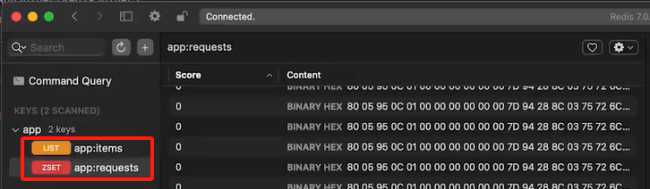
这节课老师的项目名也是app ,所以爬取的数据也是存储在app 中

祝学习愉快~
相似问题






登录后可查看更多问答,登录/注册














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星