需要登录的网站怎么爬取?
我在爬取企查查的时候 爬取一个公司的详情页页面发现 点击html代码中的a标签中的链接的时候 企查查会自动提醒登录 导致我爬不出详情页的信息 怎么解决?求大神指导
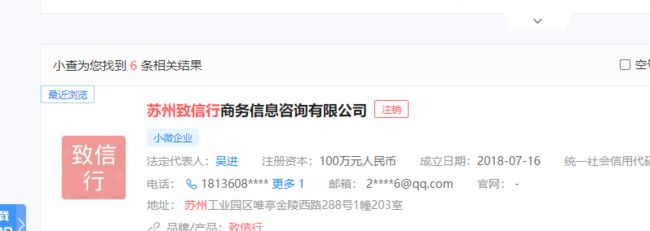

相关代码:
import scrapy
import xlrd
from qcc_excel.items import QccExcelItem
class QccExcel1Spider(scrapy.Spider):
name = 'qcc_excel_1'
allowed_domains = ['qcc.com']
# start_urls = ['http://qcc.com/']
def start_requests(self):
excel = xlrd.open_workbook('company.xlsx')
work_book = excel.sheet_by_name('Sheet1')
for k, v in work_book.get_rows():
company_list_url = 'https://www.qcc.com/web/search?key={}'.format(k.value)
yield scrapy.Request(url=company_list_url,callback=self.parse)
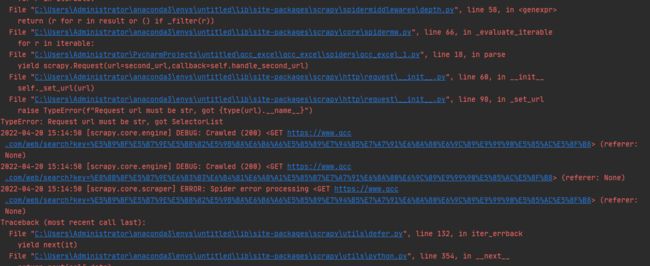
def parse(self, response,*args,**kwargs):
second_url=response.xpath('//table[@class="ntable ntable-list"]/tr[1]/td[3]/div/div/span/a/@href').extract()
yield scrapy.Request(url=second_url,callback=self.handle_second_url)
def handle_second_url(self,response):
info=QccExcelItem()
info["location"]=response.xpath('//table[@class="ntable"]/tr[6]/td[4]/text()').extract_first()
info["trades"] = response.xpath('//table[@class="ntable"]/tr[6]/td[2]/text()').extract_first()
info["business"] = response.xpath('able[@class="ntable"]/tr[10]/td[2]/text()').extract_first()
yield info9
收起
正在回答
1回答

同学,你好!可以手动带上已知有效的cookie。
1、先在浏览器登录相应的网站后,复制请求包里的Cookie字段值。
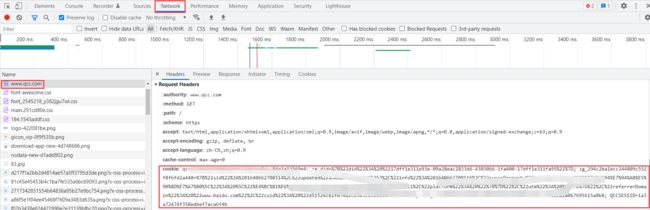
2、在爬虫的settings.py文件中,设置请求头的cookie为复制的值,并把COOKIES_ENABLED开关置为False,让scrapy不再对cookie进行额外处理。
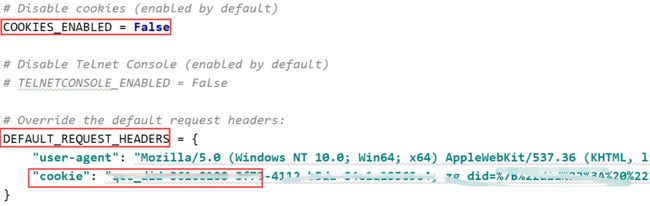

祝学习愉快!
相似问题
使用selenium需要不需要考虑反爬措施吗
17
0
3

requeset请求什么时候需要带请求头呢
26
0
3


请问课程里有教scrapy怎么携带cookie进行登录吗
16
0
6


Scrapy爬取去哪儿的问题
20
0
5


关于获取token值
24
0
3


登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星