scrapy爬取企查查 多次爬取 导致需要进行用户验证怎么办
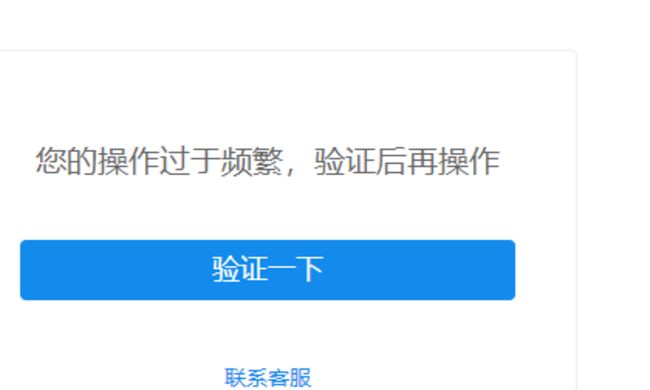
下面是爬取结果 可以看到我前面还是能爬取到信息的 爬了一会 就报412了 然后我点击那个链接 就让我进行用户验证 怎么解决?
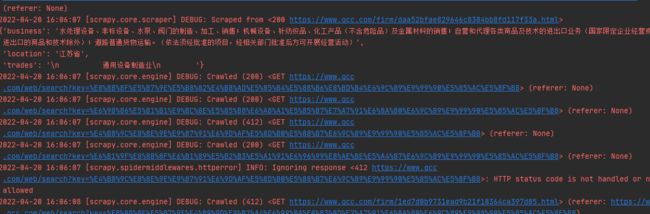
import scrapy
import xlrd
from qcc_excel.items import QccExcelItem
class QccExcel1Spider(scrapy.Spider):
name = 'qcc_excel_1'
allowed_domains = ['qcc.com']
# start_urls = ['http://qcc.com/']
def start_requests(self):
excel = xlrd.open_workbook('company.xlsx')
work_book = excel.sheet_by_name('Sheet1')
for k, v in work_book.get_rows():
company_list_url = 'https://www.qcc.com/web/search?key={}'.format(k.value)
yield scrapy.Request(url=company_list_url, callback=self.parse)
def parse(self, response, *args, **kwargs):
second_url = response.xpath(
'//table[@class="ntable ntable-list"]/tr[1]/td[3]/div/div/span/a/@href').extract_first()
yield scrapy.Request(url=second_url, callback=self.handle_second_url)
def handle_second_url(self, response):
info = QccExcelItem()
info["location"] = response.xpath('//table[@class="ntable"]/tr[6]/td[4]/text()').extract_first()
info["trades"] = response.xpath('//table[@class="ntable"]/tr[6]/td[2]/text()').extract_first()
info["business"] = response.xpath('//table[@class="ntable"]/tr[10]/td[2]/text()').extract_first()
yield info3
收起
正在回答 回答被采纳积分+1
1回答

好帮手慕凡
2022-04-20 16:19:53
同学,你好!
爬取次数太多会触发反爬,商业化的网站反爬措施都比较复杂,爬取比较困难,会有各种反爬的措施,需要不同的方案去解决,现在是已经被反爬了,同学可以尝试下使用IP代理:https://class.imooc.com/lesson/2198#mid=55544,如果反爬措施比较复杂无法爬取,则需要有针对性的研究一下反反爬技术,祝学习愉快~
相似问题




登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程
















恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星