请问output作为输入,是将全部的decoder输出作为输入么?
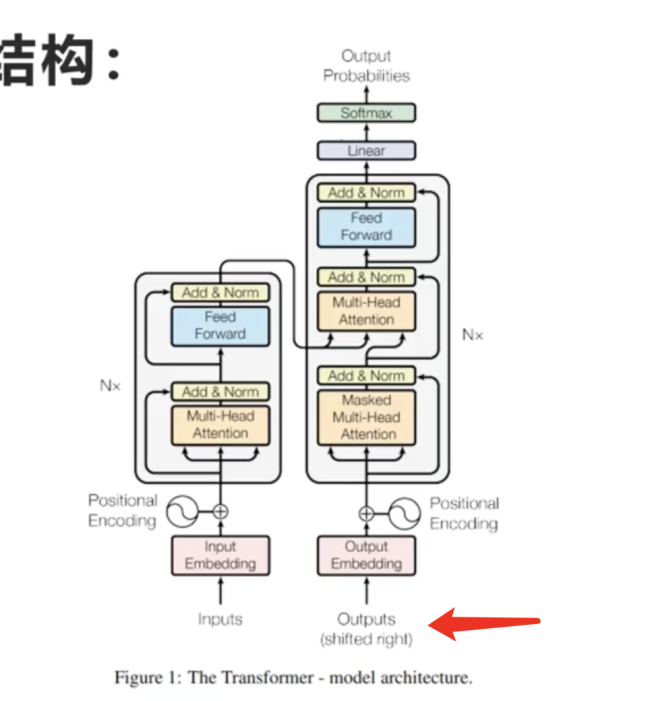
请问outputs作为输入,是将decoder前面所有输出结果作为输入么?
decoder的输出的一个概率分布,请问是将其中概率最大的字作为输出么?那要是在某一轮输出的时候预测错误,后面不会跟着越错越远么?
正在回答 回答被采纳积分+1

在Transformer模型中,decoder的输入包括了来自encoder的信息以及之前decoder层的输出。当将decoder的输出作为输入时,通常是将前面所有的输出结果作为输入,而不是只将概率最大的字作为输入。 请注意,解码器本身并不输出 tokens,而是输出 logits(数量与词汇表的大小相同)(logits 是一个数值向量,其维度等于词汇表的大小,表示每个 token 的可能性分数)。通过 logits 提取 tokens 的过程是通过一种被称为搜索策略(search strategy)、生成策略(generation strategy)或解码策略(decoding strategy)的启发式方法完成的。对于decoder的输出的概率分布,通常会选择概率最大的字作为输出。这种方法被称为贪婪解码。然而,在某些情况下,贪婪解码可能会导致错误累积的问题,即在某一轮输出时预测错误可能会影响后续的输出结果。为了解决这个问题,可以使用束搜索(beam search)等方法来平衡搜索效率和准确性。 在束搜索中,会保留多个备选的输出序列,并在每一步选择概率最大的前B个作为备选,其中B是束搜索的宽度参数。这样可以一定程度上缓解错误累积的问题,但也会增加计算复杂度。 Transformer模型在解码阶段可以采用贪婪解码或束搜索等方法,以平衡准确性和效率之间的权衡










- 参与学习 240 人
从入门-案例实战-多领域应用-面试指导-推荐就业,匹配课前知识路线、详细学习笔记和全方位服务,助力学习与就业,快速实现职业跃迁。附赠价值2000元+的大模型项目代码/数据和配套环境和GPU。
了解课程


恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星