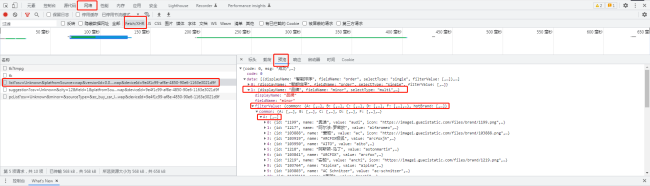
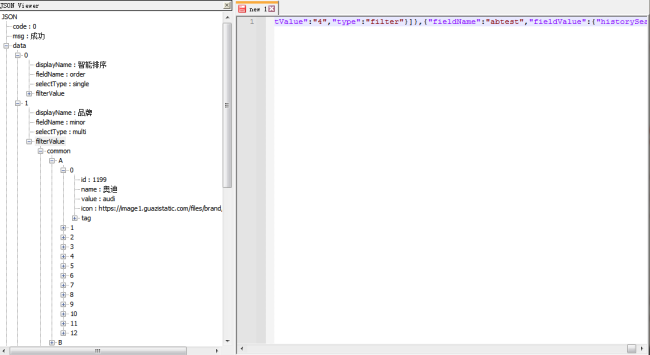
请问现在common里的value找不到相应的汽车品牌了,应该怎么找呢
而且网页内文本内容几乎没有所要找的汽车品牌的信息

import requests
url="https://mapi.guazi.com/car-source/carList/pcList?osv=Unknown&minor={}&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=7&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=562084751130124288&platfromSource=wap&versionId=0.0.0.0&sourceFrom=wap&deviceId=b3739738-67cf-4717-8771-de994bc63a6a"
header={
"client-time": "1658075729",
"verify-token": "ce1b9dfd413fc620cb2a4bad9d8c378e",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
}
response=requests.get(url=url,headers=header)
with open("brands_dazhong.txt","w",encoding="utf-8") as f:
f.write(response.text)import scrapy
import json
class GuaziSpider(scrapy.Spider):
name = 'guazi'
allowed_domains = ['guazi.com']
# start_urls = ['http://guazi.com/']
def start_requests(self):
#发送列表页请求
with open("brands.txt","r",encoding="utf-8") as f:
brands_data=f.read()
brands_list=json.loads(brands_data).get("data").get("hot_keywords")
for brand in brands_list:
url="https://mapi.guazi.com/car-source/carList/pcList?osv=Unknown&minor={}&sourceType=&ec_buy_car_list_ab=&location_city=&district_id=&tag=-1&license_date=&auto_type=&driving_type=&gearbox=&road_haul=&air_displacement=&emission=&car_color=&guobie=&bright_spot_config=&seat=&fuel_type=&order=7&priceRange=0,-1&tag_types=&diff_city=&intention_options=&initialPriceRange=&monthlyPriceRange=&transfer_num=&car_year=&carid_qigangshu=&carid_jinqixingshi=&cheliangjibie=&page=1&pageSize=20&city_filter=12&city=12&guazi_city=12&qpres=562070876095696896&platfromSource=wap&versionId=0.0.0.0&sourceFrom=wap&deviceId=82c54aeb-cfe4-414a-aabb-c7c4dadb4c1b".format(brand.get("filterValue"))
yield scrapy.Request(url=url,callback=self.parse)
#仅发送第一页请求,限定在一个品牌中的
break
def parse(self, response):
pass21
收起
正在回答 回答被采纳积分+1
1回答












4.入门主流框架Scrapy与爬虫项目实战
- 参与学习 人
- 提交作业 107 份
- 解答问题 1672 个
Python最广为人知的应用就是爬虫了,有趣且酷的爬虫技能并没有那么遥远,本阶段带你学会利用主流Scrapy框架完成爬取招聘网站和二手车网站的项目实战。
了解课程







恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星