关于爬虫的问题
# coding:utf-8
import requests
from bs4 import BeautifulSoup
def work_bs4(content):
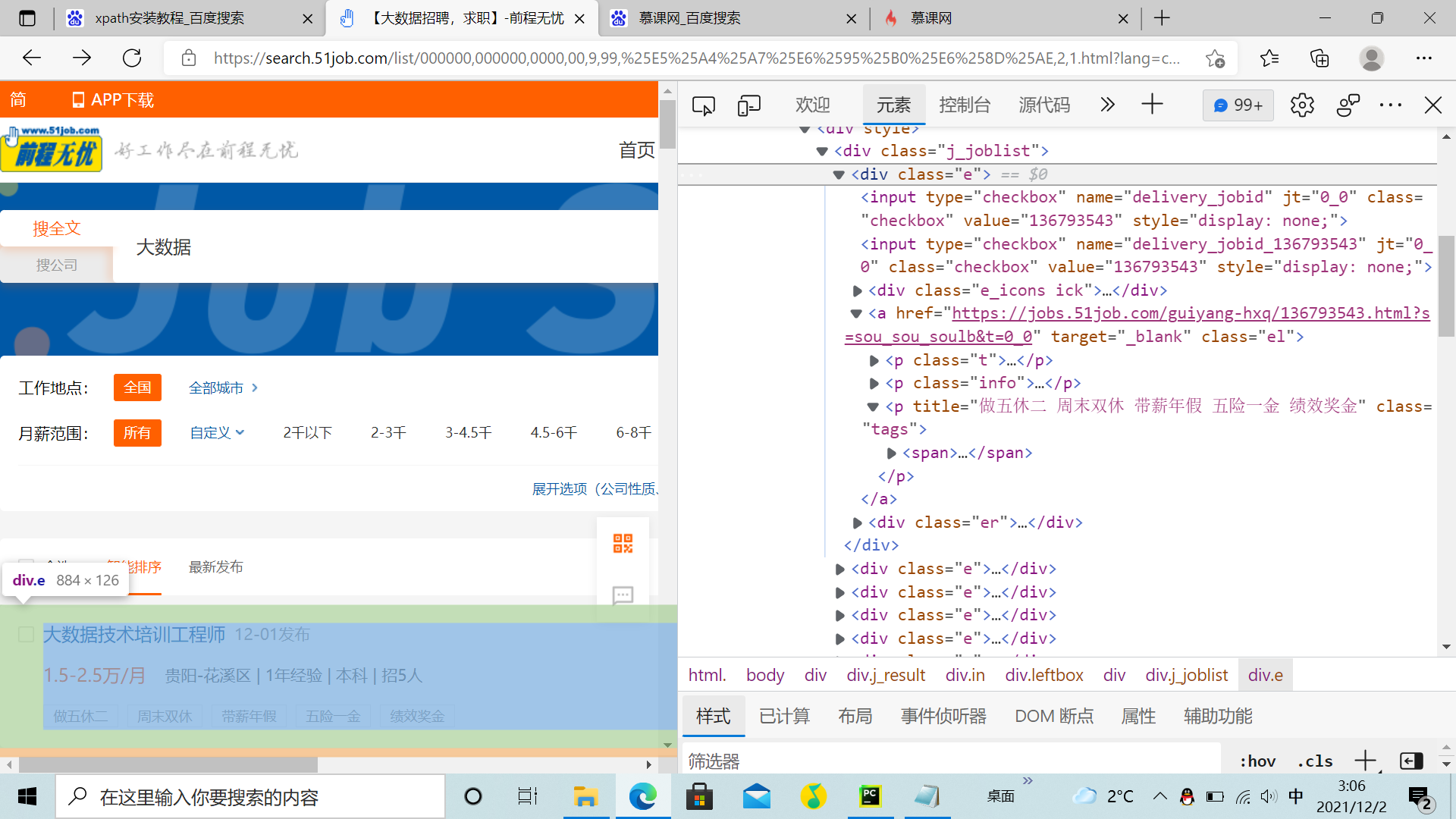
soup = BeautifulSoup(content,'lxml')
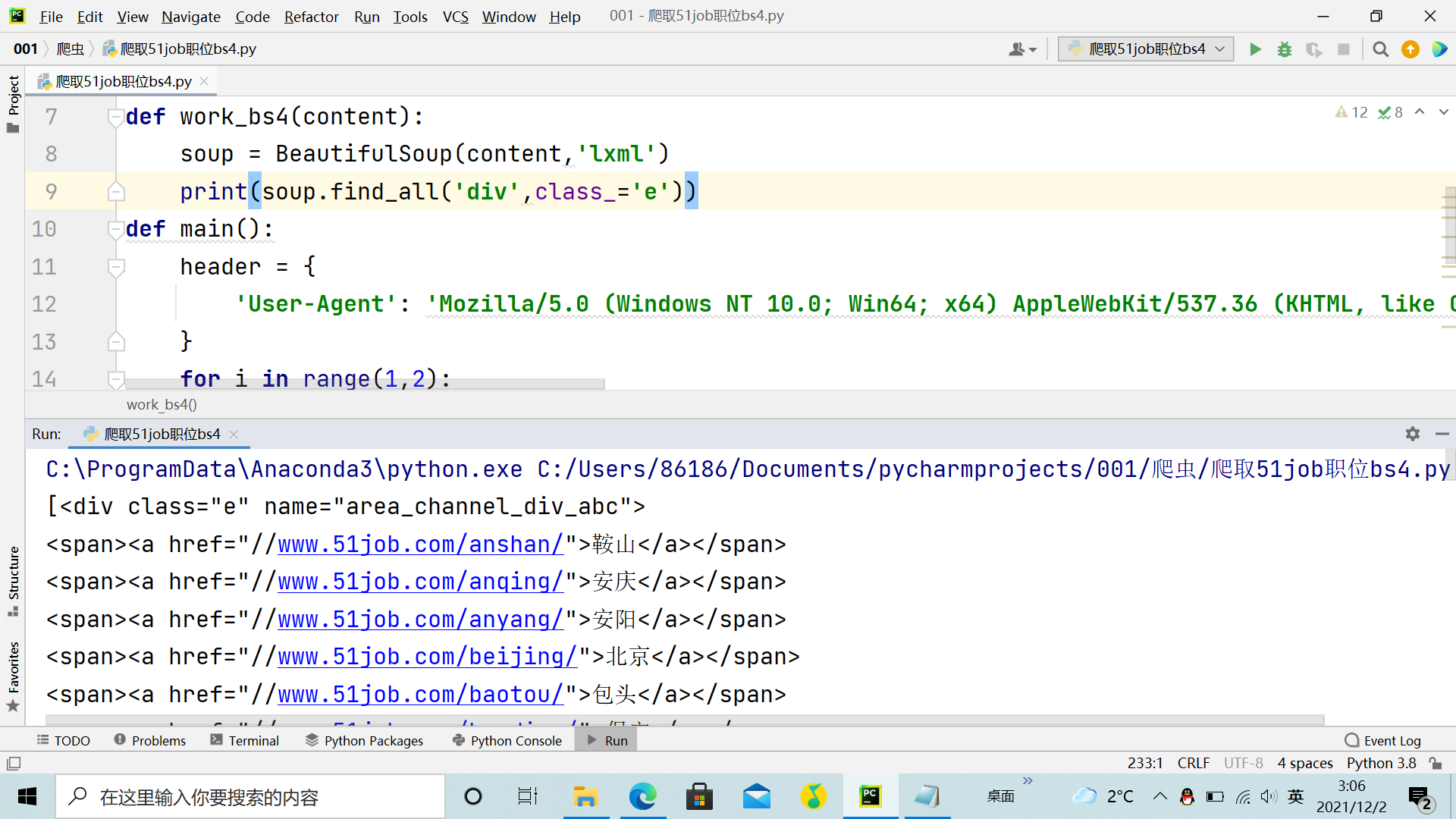
print(soup.find_all('div',class_='e'))
def main():
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34'
}
for i in range(1,2):
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='.format(i)
response = requests.get(url = url,headers = header)
work_bs4(response.text)
if __name__ == '__main__':
main()老师为什么我用soup.find_all('div',class_='e')打印出来的跟网页的不一样
8
收起
正在回答 回答被采纳积分+1
1回答
相似问题
关于爬虫爬取数据的问题
14
0
3


问题
10
0
3


关于第2章正则表达式的应用
9
0
3


爬虫中间件和下载中间件, 作用分别是什么
18
0
5


关于web服务器和爬虫程序的部署提问
4
0
1
登录后可查看更多问答,登录/注册
Python全能工程师
- 参与学习 人
- 提交作业 16435 份
- 解答问题 4469 个
全新版本覆盖5大热门就业方向:Web全栈、爬虫、数据分析、软件测试、人工智能,零基础进击Python全能型工程师,从大厂挑人到我挑大厂,诱人薪资在前方!
了解课程














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星