如果是JS动态渲染的页面,爬虫该怎么解决
问题描述:
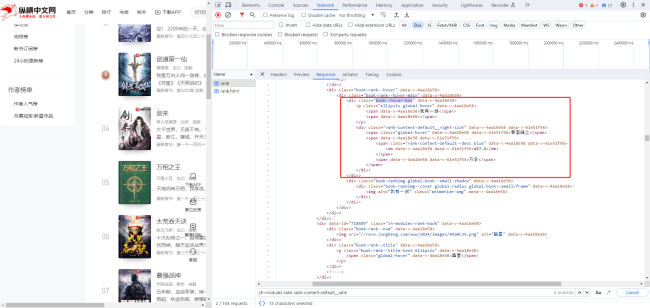
纵横中文网更新之后,跟视频里面呈现的不太一样。
我抓了一下这个位置的div。没有抓到。
相关截图:
相关代码:
import requests
from lxml import etree
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def parse(url):
res = requests.get(url, headers=headers)
tree = etree.HTML(res.text)
# print(res.text)
items = tree.xpath('//div[@class="book--hover-box"]')
print(items)
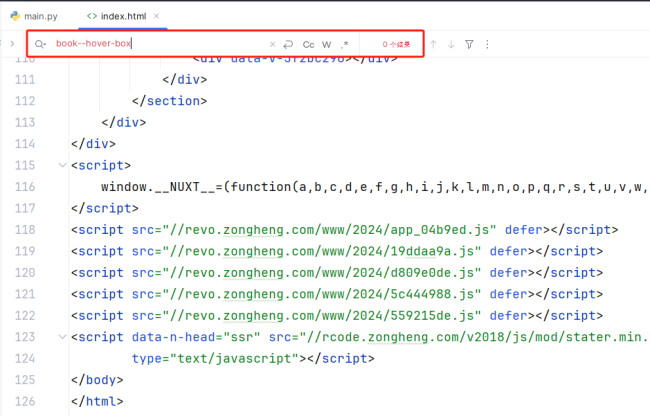
parse('https://www.zongheng.com/rank?nav=one-day&rankType=3')print出来的是一个空数组。
于是我把网页存下来,然后查了一下是否存在这个DOM元素。没有找到
相关代码:
with open('./docs/index.html', "w", encoding="utf-8") as f:
f.write(res.text)相关截图:
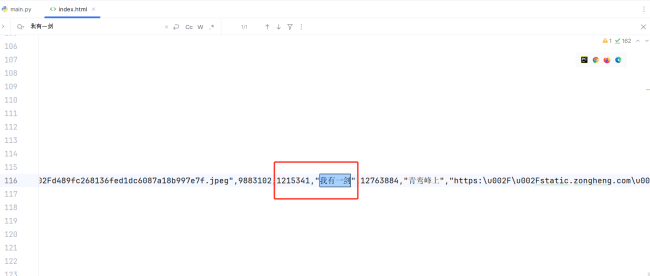
我拿书名去查了一下,发现是写在JS脚本里的。
相关截图:
问题描述:
学的不深入,不知道遇到这种情况该怎么解决。
如果只是想获取书名以及书籍ID,直接看JS代码就可以了。但如果是这样,就不算是爬虫了。
所以请教一下老师,如果还是想以爬虫的方法,来扒取这个页面上的书名以及书籍详情页链接,该如何实现。
5
收起
正在回答 回答被采纳积分+1

相似问题
老师请问 浏览器渲染页面过程 这一块知识点在那里讲到过
20
1
3


为什么就这么简单的数据还要单独用js渲染?
19
0
3
动态渲染出来的数据是没有html的吗
7
0
3


关于页面渲染
8
0
3


spa前端渲染项目,fp fcp这些统计还有意义不?
27
0
5


登录后可查看更多问答,登录/注册














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星