老师,像这种两个页面之间的url没有变化的网站,我应该怎么做才能实现翻页爬取呢

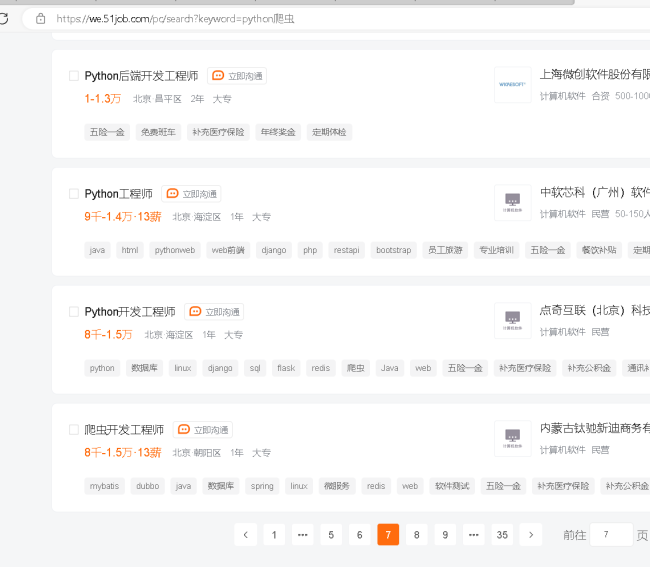
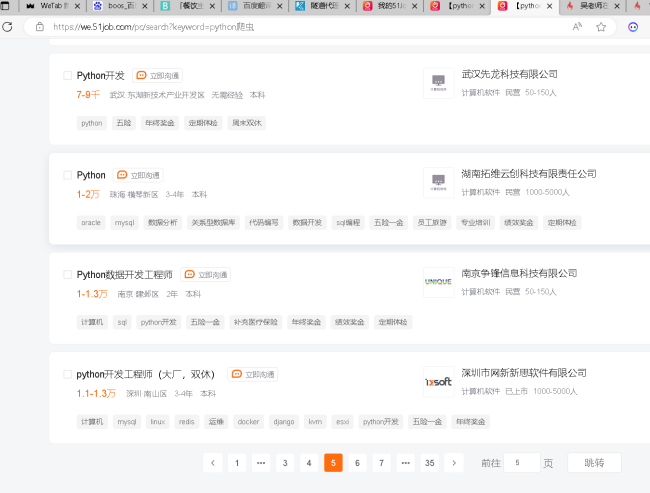
8
收起
正在回答
1回答

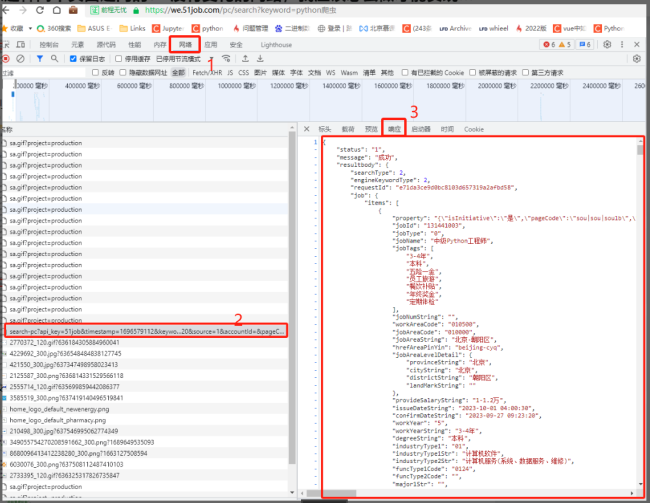
同学,你好!同学找的url接口不对,在搜索框中输入“python 爬虫”后,浏览器选择网络,点击搜索按钮可以看到所有的请求
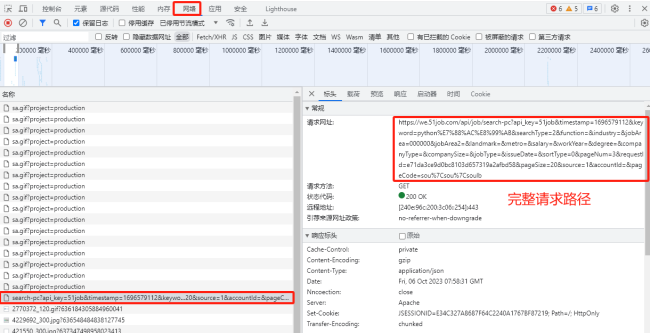
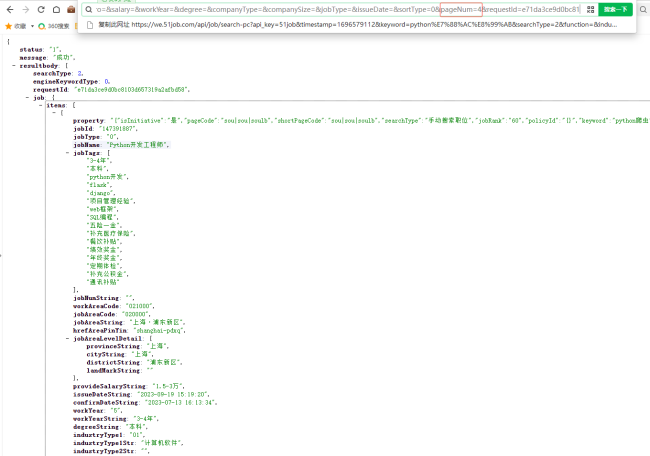
可以找到如下url是返回不同页数的内容
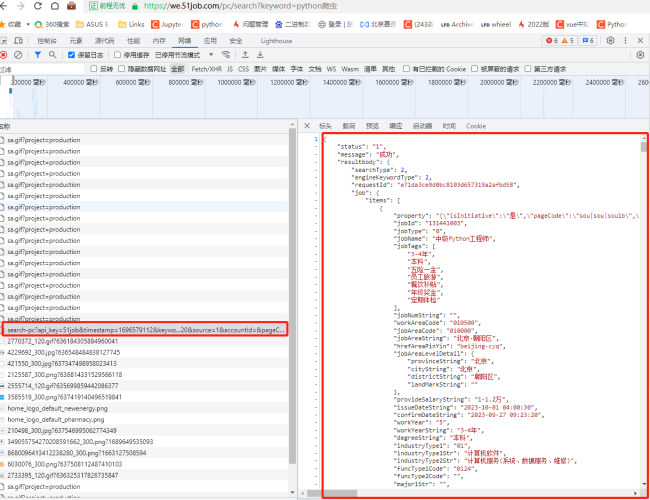
同学修改pageNum参数就可以获取想要页的数据
祝学习愉快~
相似问题





登录后可查看更多问答,登录/注册














恭喜解决一个难题,获得1积分~
来为老师/同学的回答评分吧
0 星